4. Go / ANTLR – vCard Reader#
Im letzten Kapitel wurde die Konvertierung einer VCF-Datei in CSV und zurück mittels eines in Python und unter Einsatz des Compiler-Tools (ANTLR).
Es hat sich in vielen Projekten gezeigt, dass diese Kombination aus Python und ANTLR sehr mächtig und komfortabel ist, aber man sich manchmal etwas mehr Performance wünscht.
An dieser Stelle tritt „Go“ auf den Plan. „Go“ ist eine relativ junge Programmiersprache die unter anderem vom „C-Urgestein“ B. W. Kernighan mit entwickelt wurde.
Am konkreten Beispiel soll evaluiert werden, ob eventuell der Einsatz von „Go“ Vorteile (oder welche Nachteile) uns bringen kann.
4.1. Download#
Das Script kann als ferig compiliertes Programm für Linux (amd64) oder den RaspberryPi (32 bit) heruntergeladen werden:
Linux-Version
Hier geht es zum Download:
vcfConvert-amd64-linux.RaspberryPi-Version
Hier geht es zum Download:
vcfConvert-386-pi.
Bemerkung
Falls – wider Erwarten – eine Windows-Version benötigt wird, bitte Feedback geben.
4.2. So geht’s#
Bemerkung
Der Konverter ist eine „Standalone-Applikation“, die in einer „shell“ ausgeführt wird und im Gegensatz zu Python keine runtime-Umgebung benötigt.
Das „User-Interface“ ändert sich nur geringfügig zum vorherigen Kapitel und damit auch nicht die Nutzung.
Die einzelnen Schritte.
Exportiere die Kontaktdaten des Smartphones in eine VCF-Datei, z.B.:
/tmp/phone.vcf
Erstelle aus phone.vcf eine Datei im CSV-Format, dass man mit Libreoffice oder Excel öffnen und bearbeiten kann
$ vcfConvert -input /tmp/phone.vcf --csv /tmp/adr.csv
Bemerkung
Duplikate sind in der Ausgabe entfernt worden.
Erstelle sicherheitshalber eine Arbeitskopie
cp /tmp/adr.csv /tmp/work_adr.csv
Bearbeite die Arbeitskopie work_adr.csv mit Libreoffice oder Excel.
Erstelle aus der CSV-Datei eine neue VCF-Datei mit korrigierten Daten für den Import im neuen Smartphone oder per Thunderbird.
$ ./csv2vcf.py --csv_datei /tmp/work_adr.csv result: report.d/vcf_ausgabe.vcf
Hinweis:
Warnung
An dieser Stelle wurde das Python-Programm aus dem letzten Kapitel verwendet.
Importiere die neue, überarbeitete VCF-Datei vcf_ausgabe.vcf.
4.3. Grammatik#
An der zugrundeliegenden Grammatik hat sich absolut nichts geändert:
Es wird die bekannte VCF-Spezifikation vom „versit Consortium“ implementiert.
Die selbe ANTLR Grammatik wird eingesetzt.
Die Prüfung der Grammaik selber ändert sich nicht.
4.4. ANTLR Generatoren#
Auf Basis dieser Grammatik kann ANTLR (siehe Referenzen) Basis-Klassen für verschiedene Programmiersprachen generieren. Diese Basisklassen müssen nur angepasst werden, um den kompletten Parser zu erhalten.
Bemerkung
Es wird hier vorausgesetzt, dass antlr-4.9-complete.jar lokal installiert ist unter /opt/antlr/antlr4.
Um die Basisklassen für python3 zu erhalten, wird wie folgt vorgegangen:
Die Grammatik wird in einer Datei mit Namen Qlang.g4 gespeichert.
Es wird folgender Aufruf genutzt:
java -jar /opt/antlr/antlr4/antlr-4.9-complete.jar -Dlanguage=Go QLang.g4 -o <Pfad>
Anschliessend findet man die folgenden generierten Go-Dateien vor
qlang_base_listener.go qlang_base_visitor.go qlang_lexer.go qlang_listener.go qlang_parser.go qlang_visitor.go
Go Module initialisieren
Für dieses Projekt wurde der Parser in dem Pfad $GOPATH/tgc.de/vcf/parser abgelegt. In diesem Pfad muss das Module initialisiert werden
go mod init tgc.de/vcf/parser
ANTLR runtime downloaden
Da der Parser selbst die ANTLF runtime nutzt, muss sie noch „nachgeladen“ werden.
Der Befehl
go mod tidy
erledigt das.
Das „Skelet-Konzept“ ist identisch zu dem vorigen Kapitel. Man findet eine Klasse vor, die für jede Produktion der Grammatik eine „enter“- und eine „exit“-Methode definiert:
// BaseQLangListener is a complete listener for a parse tree produced by QLangParser.
type BaseQLangListener struct{}
var _ QLangListener = &BaseQLangListener{}
// ...
// EnterVcf_prog is called when production vcf_prog is entered.
func (s *BaseQLangListener) EnterVcf_prog(ctx *Vcf_progContext) {}
// ExitVcf_prog is called when production vcf_prog is exited.
func (s *BaseQLangListener) ExitVcf_prog(ctx *Vcf_progContext) {}
Die Namen der Methoden enden entweder mit dem Namen der Regel oder mit einem selbst gewählten Namen am Ende der Regel (hier: „# vcf_prog“), der in der Grammatik angegeben ist – Beispiel:
prog: CRLF* (vcard)* # vcf_prog
erzeugt genau die obigen Methodennamen.
Jetzt liegt ein Go-Modul vor, dass unseren VCF-Parser realisiert, allerdings noch ohne irgendwelche Aktionen – d.h. es ist eine Ableitung des Listeners zu erstellen.
Wenn man „scharf“ hinschaut, sieht man was Objekt-Orientierung in Go bedeutet.
Dazu sei das [GoBook] zitiert
Although there is no universally accepted definition of object-oriented
programming, for our purposes, an object is simply a value or variable
that has methods, and a method is a function associated with a particular type.
4.5. Der eigene Listener#
Wir müssen wie zuvor in Python eine „abgeleitet“ Klasse mit den relevanten Methoden erstellen.
Das kann beispielseise wie folgt codiert weden:
1// Package vcf reads VCF-Files.
2package reader
3
4import (
5 "github.com/antlr/antlr4/runtime/Go/antlr"
6 "github.com/rs/zerolog/log"
7 "io"
8 "mime/quotedprintable"
9 "strings"
10 "tgc.de/vcf/parser" // <- ANTLR Lexer, Parser, ...
11)
12
13type vcfListener struct {
14 *parser.BaseQLangListener
15
16 vc Vcard // current vcard
17 result string
18 encoding string
19 isQuotprint bool
20 isBase64 bool
21 val string // tmp value storage
22}
23
24
25func decodeQuoted(s string) string {
26 valStr, err := io.ReadAll(quotedprintable.NewReader(strings.NewReader(s)))
27 if err != nil {
28 log.Error().Msgf("problems with quoted string: '%s'", s)
29 }
30 return string(valStr)
31}
32
33// ExitVcf_prog is called when production vcf_prog is exited.
34func (s *vcfListener) ExitVcf_prog(ctx *parser.Vcf_progContext) {
35 log.Info().Msg("prog")
36 s.result = "IO"
37}
38
39// ExitVcf_begin is called when production vcf_begin is exited.
40func (s *vcfListener) ExitVcf_begin(ctx *parser.Vcf_beginContext) {
41 log.Info().Msg("begin")
42 s.vc = Vcard{}
43}
44
45// ExitVcf_end is called when production vcf_end is exited.
46func (s *vcfListener) ExitVcf_end(ctx *parser.Vcf_endContext) {
47 log.Info().Msgf("%v", s.vc)
48 vcardResult.add(s.vc)
49}
50
51// EnterItem_rec is called when production item_rec is entered.
52func (s *vcfListener) EnterItem_rec(ctx *parser.Item_recContext) {
53 s.encoding = ""
54 s.isQuotprint = false
55 s.isBase64 = false
56}
57
58// EnterQuotprint is called when production quotprint is entered.
59func (s *vcfListener) EnterQuotprint(ctx *parser.QuotprintContext) {
60 s.isQuotprint = true
61}
62
63// ExitValue is called when production value is exited.
64func (s *vcfListener) ExitValue(ctx *parser.ValueContext) {
65 s.val = ctx.GetText()
66 if s.isQuotprint {
67 valStr := decodeQuoted(s.val)
68 log.Debug().Msgf("quoted: '%s' -> '%s'", s.val, valStr)
69 s.val = valStr
70 }
71}
72
73// ExitN_family is called when production n_family is exited.
74func (s *vcfListener) ExitN_family(ctx *parser.N_familyContext) {
75 s.vc.Family = s.val
76}
77
78// ExitN_given is called when production n_given is exited.
79func (s *vcfListener) ExitN_given(ctx *parser.N_givenContext) {
80 s.vc.Family = s.val
81}
82
83// ExitN_add is called when production n_add is exited.
84func (s *vcfListener) ExitN_add(ctx *parser.N_addContext) {
85 s.vc.Middle = s.val
86}
87
88// ExitN_prefix is called when production n_prefix is exited.
89func (s *vcfListener) ExitN_prefix(ctx *parser.N_prefixContext) {
90 s.vc.Prefix = s.val
91}
92
93// ExitN_suffix is called when production n_suffix is exited.
94func (s *vcfListener) ExitN_suffix(ctx *parser.N_suffixContext) {
95 s.vc.Suffix = s.val
96}
97
98// ExitName_rhs is called when production name_rhs is exited.
99func (s *vcfListener) ExitName_rhs(ctx *parser.Name_rhsContext) {
100
101}
102
103// ExitForm_name is called when production form_name is exited.
104func (s *vcfListener) ExitForm_name(ctx *parser.Form_nameContext) {
105 prop := s.val
106 log.Debug().Msgf("FN: %s", prop)
107 s.vc.Fn = prop
108}
109
110// ExitTelefon is called when production telefon is exited.
111func (s *vcfListener) ExitTelefon(ctx *parser.TelefonContext) {
112 prop := s.val
113 log.Debug().Msgf("Telefon: %s", prop)
114 s.vc.Tel = append(s.vc.Tel, prop)
115}
116
117// ExitVcf_mail is called when production vcf_mail is exited.
118func (s *vcfListener) ExitVcf_mail(ctx *parser.Vcf_mailContext) {
119 prop := s.val
120 log.Debug().Msgf("Mail: %s", prop)
121 s.vc.Mail = prop
122}
123
124// ExitCategorie is called when production categorie is exited.
125func (s *vcfListener) ExitCategorie(ctx *parser.CategorieContext) {
126 prop := s.val
127 log.Debug().Msgf("Categorie: %s", prop)
128 s.vc.Mail = prop
129}
130
131// ExitTitle is called when production title is exited.
132func (s *vcfListener) ExitTitle(ctx *parser.TitleContext) {
133 prop := s.val
134 log.Debug().Msgf("Title: %s", prop)
135 s.vc.Title = prop
136}
137
138
139// ExitOrg is called when production org is exited.
140func (s *vcfListener) ExitOrg(ctx *parser.OrgContext) {
141 prop := s.val
142 log.Debug().Msgf("Org: %s", prop)
143 s.vc.Org = prop
144}
Die Implementierung ist der Python-Variante erstaunlich ähnlich. Auf einige kleine, feine Unterschiede sei allerdings hingewiesen:
Zeile 10
Es wird das Modul importiert, das zuvor durch den Generator erstellt wurde.
Zeile 10
Go kennt kein Konzept von Basis-Klassen und Ableitungen sondern wirklich nur struct {} mit Methoden.
Um trotzdem die Basis zu nutzen, die der Generator erzeugt hat, wird ein neuer struct vcfListener definiert, der einen Pointer auf parser.BaseQLangListener hat.
Das ist eine „has-a“-Beziehung und nicht eine „is-a“.
Weil in solchen „Komposotionen“ von structs auch auf die Methoden der „unnamed“ Komponenten direkt zugegriffen werden kann, werden diese scheinbar „vererbt“.
Zeile 16
Ein weiterer neuer Daten-Typ, struct Vcard dient als Container für eine Adresse (mehr dazu unten).
Zeile 42
Nach dem Lesen einer „BEGIN“ Zeile wird diese Methode getriggert und ein leeres Vcard-Objekt als Speicher allokiert.
Zeile 48
Nach dem Lesen der „END“ Zeile wird der gefüllte Speicher in einer vcardResult struct mit der Methode add() abgelegt zur späteren Verarbeitung.
Analog dem Python-Programm wurden Daten-Container „Klassen“ definiert:
1type VcardName struct {
2 Family string
3 Given string
4 Middle string
5 Prefix string
6 Suffix string
7}
8
9type Vcard struct {
10 VcardName
11 Fn string
12 Tel []string
13 Mail string
14 Categorie string
15 Org string
16 Title string
17}
18
19type VcardResult struct {
20 mux sync.Mutex
21 cardHash map[string]Vcard
22}
23
24// address container
25var vcardResult = VcardResult{}
26
27// add appends a new Vcard to the result
28func (r *VcardResult) add(adr Vcard) {
29 // k := adr.vcName()
30 r.mux.Lock()
31 defer r.mux.Unlock()
32
33 k := adr.Fn
34 _, ok := r.cardHash[k]
35 if ! ok {
36 r.cardHash[k] = adr
37 } else {
38 log.Info().Msgf("duplicate adress: %s", k)
39 }
40}
Im Gegensatz zu Python bekommt man die Initialisierung dieser „Container“ geschenkt und muss nicht explizit Funktionen dafür schreiben.
In Zeile 20 wurde ein Mutex mit aufgenommen, um bei Parallelbetrieb (goroutinen) die korrekte Bearbeitung des Ergebnis-Hashes sicherzustellen.
Die Methode add in Zeile 28 nutzt den Mutex, um den Zugriff auf cardHash abzusichern. Zeile 31 stellt sicher, daß der Mutex wieder freigegeben wird, unabhängig davon was in der Methode sonst so passiert.
4.6. Das Hauptprogramm#
Das VCF-Go-Projekt wurde in 3 Komponenten aufgeteilt, die als Module implementiert sind. Die Struktur ist folgendermaßen unterhalb von $GOPATH
.
└── tgc.de
└── vcf
├── main <- main Methode
├── parser <- Ausgabe von ANTLR
└── reader <- Ableitungen vom Base-Listener, Parser, Writer
Es wurde zunächst analog der Python-Version vorgegangen:
Lese alle VCF-Adressen als string ein.
Verarbeite den string durch den Parser.
Weil später noch Optimierungen durch Parallelisierung (goroutinen) geplant sind, wurde für den ersten Ansatz eine Methode reader.ParseComplete geschrieben, die im main-Programm aufgerufen wird:
1// Package main for VCF-Parser. 2package main 3 4import ( 5 // ... 6 "tgc.de/vcf/reader" 7) 8 9var ( 10 // infile = "/aph/projekte/intern/2021/02_vcf_reader/Src/data/phone.vcf" 11 infile = "/tmp/phone.vcf" 12 outfile = "/tmp/adr.csv" 13 argInput *string 14 argCsv *string 15 argParallel *bool 16 argSingle *bool 17 mod string 18) 19 20func main() { 21 readArgs() 22 23 switch mod { 24 case "normal": 25 reader.ParseComplete(*argInput, *argCsv) 26 case "single": 27 reader.ParseSingle(*argInput, *argCsv) 28 case "parallel": 29 reader.ParseSingleParallelWithLimit(*argInput, *argCsv) 30 case "nolimit": 31 reader.ParseSingleParallelNoLimit(*argInput, *argCsv) 32 } 33}
reader.ParseComplete hat zwei string-Parameter: der Pfad der VCF-Eingabedatei und der Pfad der CSV Ausgabe.
Die Implementierung von reader.ParseComplete ist ziemlich simpel:
1// ParseComplete reads the complete input file for parsing 2func ParseComplete(infile, outfile string) { 3 start := time.Now() 4 data, err := ioutil.ReadFile(infile) 5 if err != nil { 6 log.Fatal().Err(err).Msg("Terminating") 7 } else { 8 log.Printf("reading: %s", infile) 9 } 10 log.Info().Msgf("read time: %2fs", time.Since(start).Seconds()) 11 12 start = time.Now() 13 _ = VCFParser(string(data)) 14 log.Info().Msgf("parse time: %2fs", time.Since(start).Seconds()) 15 16 WriteCsv(outfile) 17}
Die Markierungen zeigen die relevanten Aktionen: Einlesen, Parsen und CSV schreiben. Der Rest ist Fehlerbehandlung und Logging zur Messung der Laufzeit.
Die Methode VCFParser arbeitet ebenfalls analog der Python-Implementierung nach typischen ANTLR-Muster:
1// VCFParser takes a string as VCF input and parses it. 2func VCFParser(input string) string { 3 // Setup the input 4 is := antlr.NewInputStream(input) 5 6 // Create the Lexer 7 lexer := parser.NewQLangLexer(is) 8 stream := antlr.NewCommonTokenStream(lexer, antlr.TokenDefaultChannel) 9 10 // Create the Parser 11 p := parser.NewQLangParser(stream) 12 13 // Finally parse the expression (by walking the tree) 14 var listener vcfListener 15 antlr.ParseTreeWalkerDefault.Walk(&listener, p.Prog()) 16 17 return "IO" 18}
In Zeile 14 wird ein Objekt unser vcfListener-Klasse instanziert, um in Zeile 15 an der AST-Tree-Walker übergeben zu werden.
4.7. Performance-Vergleich I#
Nun soll die spannende Frage geklärt werden: bringt die Nutzung einer anderen Sprache als Python bei Einsatz der selben Tool-Chain (ANTLR) Vorteile in der Ausführungsgeschwindigkeit?
Unsere VCF-Testdatei hat ca. 60 KB Umfang mit 432 Adressen.
Sowohl Go als auch Python lesen diese kleine Datei in deutlich weniger als 1 ms ein. Das gilt auch, wenn alle Linux-Caches geleert werden. Der Parser benötigt demgegenüber ein Vielfaches an Zeit, so daß bei der Gegenüberstellung nur die reine Parser-Zeit berücksichtigt wird.
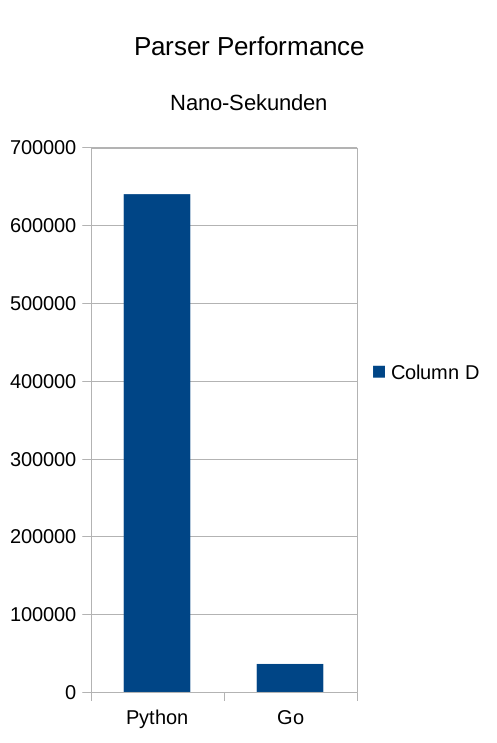
Die Verarbeitunszeit ist wie folgt
Python 0,640000 Sekunden
Go 0,036000 Sekunden
Visualisiert man das Ergebnis wird der Unterschied sehr deutlich:
Warnung
Go ist 17 mal schneller.
4.8. Optimierungen – Go-Routinen#
4.8.1. G2#
Mit seinen Go-Routinen bietet Go eine einfache Möglichkeit, Funktionen und Methoden parallel abarbeiten zu lassen. Mit Hilfe sogenannter Chanel lassen sich die parallelen Prozesse synchronisieren und/oder limitieren. In Zeiten, wo fast jeder Rechner über mehrere Cores verfügt, könnte eine solche Parallelisierung also tatsächlich die „real-time“ kürzer machen als die „user-time“.
$ time vcfConvert
Set log file to: /tmp/vcfConvert.log
Write comments to: [email protected]
real 0m0.045s
user 0m0.037s
sys 0m0.016s
Welche Möglichkeiten hat man, im konkreten Beispiel das Parsing zu parallelisieren? Eine erste Idee ist: verarbeite nicht die komplette Datei sondern einzelne Adressen; also alle Zeilen zwischen einem BEGIN und END.
In einer ersten Version wurde eine Parser-Methode geschrieben, die alle Adressen einzeln verarbeitet aber ohne Parallelisierung – einfach als Vergleich zum „brute force“ Vorgehen beim Lesen des gesamten Inputs: reader.ParseSingle in der main-Funktion.
1// Package main for VCF-Parser. 2package main 3 4// ... 5 6func main() { 7 readArgs() 8 9 switch mod { 10 case "normal": 11 reader.ParseComplete(*argInput, *argCsv) 12 case "single": 13 reader.ParseSingle(*argInput, *argCsv) 14 case "parallel": 15 reader.ParseSingleParallelWithLimit(*argInput, *argCsv) 16 case "nolimit": 17 reader.ParseSingleParallelNoLimit(*argInput, *argCsv) 18 } 19}
reader.ParseSingle wird wie folgt implementiert:
1// ParseSingleStream reads inout as stream and parses single addresses 2func ParseSingle(infile, outfile string) { 3 fh, err := os.Open(infile) 4 if err != nil { 5 log.Fatal().Err(err).Msg("Terminating") 6 } else { 7 log.Printf("reading: %s", infile) 8 } 9 10 input := bufio.NewScanner(fh) 11 count := 0 12 buf := bytes.Buffer{} 13 start := time.Now() 14 for input.Scan() { 15 cl := input.Text() 16 17 if strings.HasPrefix(cl, "BEGIN:") { 18 buf = bytes.Buffer{} 19 } 20 21 _, err = buf.Write([]byte (cl + "\n")) 22 if err != nil { 23 log.Fatal().Err(err).Msg("Terminating") 24 } 25 26 if strings.HasPrefix(cl, "END:") { 27 VCFParser(buf.String()) 28 } 29 30 count += 1 31 } 32 33 log.Info().Msgf("parse time: %2fs", time.Since(start).Seconds()) 34 log.Info().Msgf("line count: %d", count) 35 WriteCsv(outfile) 36}
Beim Lesen von BEGIN wird in Zeile 18 ein leerer Buffer erzeugt. In diesen Buffer wird jede Input Zeile (Zeile 21) geschrieben. Wenn eine Adresse komplett erkannt wurde durch Lesen von END wird die bekannte Parser-Methode gestartet mit dem Inhalt des Buffers (Zeile 27).
Diese Implementierung des Parsers soll „G2“ genannt werden, um sie von der ersten (G1) unterscheiden zu können.
Da mit dem gerade beschriebenen Ansatz nichts parallelisiert wurde, können wir eine Performanceverbesserung nicht unbedingt erwarten. Es könnte aber sein, daß das Parsen vieler kleiner Eingaben effizienter ist als das eines „großen“ Input-Streams.
Die tatsächlichen Ergebnisse heben wir etwas auf, bis zwei Strategien der Parallelisierung vorgestellt sind.
4.8.2. G3#
In dieser Version werden die Adressen eingelesen und eine einer Liste gespeichert. Alle Elemente der Liste werden dann von Go-Routinen abgearbeitet. Es wird nicht kontrolliert, wieviel Go-Routinen maximal aktiv sind.
Die Methode reader.ParseSingleParallelNoLimit implementiert das Vorgehen.
1// ParseSingleParallelWithLimit parses single addresses no concurrency limit 2func ParseSingleParallelNoLimit(infile, outfile string) { 3 adrLst := readAddresses(infile) 4 start := time.Now() 5 var wg sync.WaitGroup 6 7 for _, adr := range adrLst { 8 wg.Add(1) 9 10 go func(text string) { 11 defer wg.Done() 12 VCFParser(text) 13 }(adr) 14 } 15 16 // Wait for goroutines to complete. 17 wg.Wait() 18 log.Info().Msgf("parse time: %2fs", time.Since(start).Seconds()) 19 WriteCsv(outfile) 20}
Um sicherzustellen, daß das Programm erst terminiert, wenn alle Go-Routinen fertig sind, wurde eine sync.WaitGroup eingebaut. Die wird mit jeder neuen Adresse inkrementiert und bei Verlassen einer Go-Routine wieder reduziert.
Man kann zu dem Zweck auch leicht einen Chanel zu Synchronisierung verwenden.
Warnung
Keinesfalls kann man die Go-Routinen einfach starten ohne die Abarbeitung zu kontrollieren.
4.8.3. G4#
Selbst mit unserer kleinen Testdatei, die gut 400 Adressen enthält, ist es unwahrscheinlich, daß alle Adressen parallel auf einem Core bearbeitet werden können – vielleicht in 20 Jahren.
Deshalb wird die Anzahl der Go-Routinen, die parallel arbeiten, in der nächsten Version auf 4 eingeschränkt (mindestens 4 Cores haben die meisten heutigen Rechner).
Implementiert ist dieses Vorgehen in reader.ParseSingleParallelWithLimit.
1var limitChanel = make(chan bool, 4) 2 3// ParseSingleParallelWithLimit parses single addresses with limited concurrency 4func ParseSingleParallelWithLimit(infile, outfile string) { 5 syncCh := make(chan bool) 6 adrLst := readAddresses(infile) 7 start := time.Now() 8 9 for _, adr := range adrLst { 10 go func(input string) { 11 limitChanel <- true // write token 12 defer func() { <-limitChanel }() // release token 13 14 VCFParser(input) 15 syncCh <- true 16 }(adr) 17 } 18 19 // Wait for goroutines to complete. 20 for range adrLst { 21 <-syncCh 22 } 23 24 log.Info().Msgf("parse time: %2fs", time.Since(start).Seconds()) 25 WriteCsv(outfile) 26}
limitChanel wird in Zeile 11 beschrieben. Wenn der Chanel mit 4 Adressen gefüllt ist, blockiert er weitere Eingaben. D.h. die nächste Go-Routine startet erst, wenn wieder ein Platz nach Abarbeitung (Zeile 12) frei wird.
Da sichergestellt werden muß, daß auch wirklich alle Go-Routinen fertig sind, wurde noch ein Chanel zur Synchronisierung eingefügt. Wenn alle To-Routinen ihren Job erledigt haben, kann der letzte Eintag gelesen werden (Zeile 21).
4.9. Performance-Vergleich II#
Es ist nur noch die Frage zu beantworten, wieviel (oder wenig) die Parallelisierung an Performance bringt.
Das Ergebnis ist etwas ernüchternd
Python 0,640000 sec
Go1 0,036000 sec
Go2 0,410000 sec
Go3 0,220000 sec
Go4 0,190000 sec
In Form einer Graphik sieht das auch nicht besser aus:
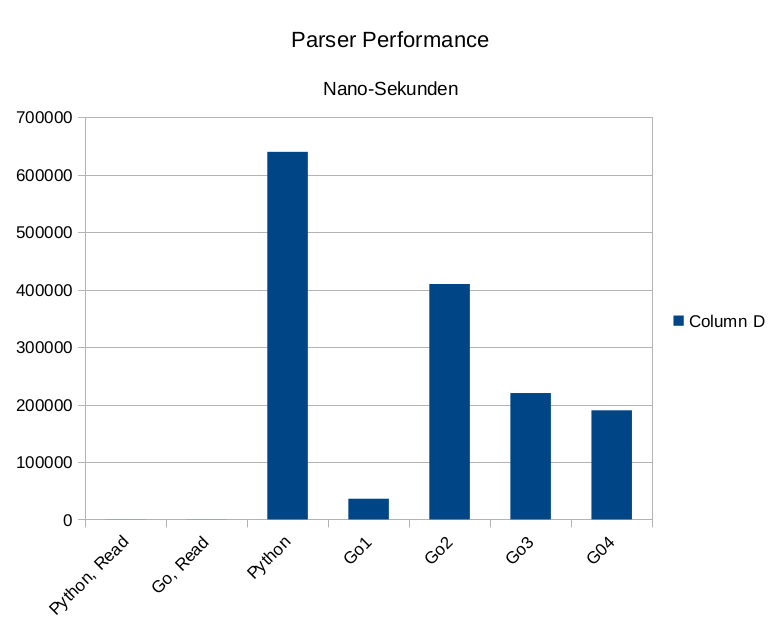
Anscheinend ist der Aufwand, den Parser jeweils für eine Adresse zu starten und die interne Verwaltung der Go-Routinen um ein Vielfaches aufwendiger als die Bearbeitung eines „großen“ Input-Streams.
Um durch Parallelisierung Performance zu gewinnen, muß man vielleicht den Input-Stream in wenige (limitChanel size) Teile zerlegen und die müssen eine gewisse Größe haben (10.000 Adressen oder so).
Bemerkung
G5, Partitionierung bleibt als Übung …
4.10. Referenzen#
Referencen
[GoBook]Alan A. A. Donovan · Brian W. Kernighan „The Go Programming Language“; http://www.gopl.io/