6. Ceph#
In diesem Kapitel soll ein Thema kurz vorgestellt werden, dass wahrscheinlich „lebenfsfüllend“ (zumindest beruflich) sein kann: Ceph.
Am Ende dieses kleinen Experiments haben wir einige GB Speicherplatz auf einem Filesystem zu Verfügung, dass das Potential für ExaByte hat – alles nur eine Frage der Hardware, die im „Proof of Concept“ natürlich etwas beschränkt ist.
$ df -hT | grep -E "cfs|Used"
Filesystem Type Size Used Avail Use% Mounted on
192.168.122.166:6789:/ ceph 37G 6.9G 30G 20% /mnt/cfs
6.1. Was ist Ceph#
Ceph ist eine (umfangreiche) Softwarelösung, die die „finale“ Lösung aller Speicherprobleme einer Firma/Institution verspricht / implementiert.
Warum gebrauche ich hier das Adjektiv „final“? Weil folgende Anforderungen realisiert werden können:
Das Speichersystem ist skalierbar, erweiterbar bis hin zu Peta- und ExaByte Datenmengen.
Es ist schnell (kann schnell sein), weil die Zugriffe parallelisiert sind.
Es ist ausfallsicher durch (hoffentlich geplante) Redundanz.
Es bedarf keiner speziellen Hardware (man muss die Hardware trotzdem richtig planen).
Es ist Opensource [1] .
Um es zu zitieren [Ceph_About] :
Ceph is highly reliable, easy to manage, and free. The power of Ceph can transform your company’s IT infrastructure and your ability to manage vast amounts of data.
Warnung
Ceph ist keine Lösung für einen Laptop oder Desktop.
Es bedarf immer mehrerer (vieler) Server (Knoten), um ein Ceph-Cluster zu erstellen.
Für diese Test- und Validierungsinstallation liegt der Fokus auf Ausfallsichheit (Storage, Platten) und Performance.
Kann man Ceph als Speicherlösung beispielsweise für die zuvor vorgestellten PostgreSQL-Cluster verwenden?
Wie verändert sich die Performance? Was ist zu beachten?
6.2. Wer braucht ExaBytes#
Da Ceph auch in den ExaByte-Bereich (EB) skaliert, sollte man sich vielleicht mal vorstellen, was das für Datenmengen sind.
Eigenschaften / Konsequenzen von ExaBytes:
Beim Einsatz von 10TB 3,5 Zoll Disks und einer Netzwerkarte mit 10 GBit je Server/Knoten, kann man an einen Knoten ca. 10 Disks anschliessen.
Für ein EB werden dann immerhin 10.000 Knoten benötigt – alternativ 1000 Knoten mit 100 Disks und 100 GBit Netzkarte.
Mit diesem Speichersystem kann man für jeden Erdenbürgen 25 Bücher mit ca 400 Textseiten speichern (100 MB).
Fast ist man geneigt zu sagen: es gibt für diese Datenmengen kaum einen Anwendungsfall.
Allerdings ist mir noch eine kuriose Idee eingefallen, die ein Vielfaches an Kapazität benötigen würde: „secure autonmous driving“. Man stelle sich vor, alle Autos der Welt sind in Zukunft mit Sensoren für „Autonmous driving“ ausgestattet und sollen diese Daten für 1 Jahr speichern zur Aufklärung des Hergangs bei Unfällen.
Zur Zeit fallen für 1 Stunde Fahrzeit ca. 1TB an Daten an.
Rechnet man dieses Volumen für 1 Jahr und 1 Millarde Fahrzeuge hoch, ergeben sich folgende Anforderungen:
100.000 EB werden benötigt.
Die Disks dieser 100 ZB werden ca. 876.000.000.000 kwh Strom verbrauchen.
Der Strompreis in Deutschland dafür wären ca. 262.800.000.000 €.
Warnung
Das ist ca. das Dreifache des Bitcoin-Stromverbrauchs im Jahr 2024 (240 TWh geschätzt).
Schon aus ökologischen Gründen wünsche ich mir, daß niemand die 100 ZetaByte Idee aufnimmt und das Bitcoin endlich abgeschafft wird.
Bemerkung
Die Berechnung der CO2 Einsparung bleibt als Übungsaufgabe ;-)
6.3. Architektur#
6.3.1. Produktion#
Eine Ceph-Speicherlösung besteht immer aus mehreren Nodes/Servern und bildet damit einen Verbund, ein Cluster.
Gemäß der Dokumentation benögigt ein minimales Ceph-Cluster verschiedene Typen von Servern:
Monitor-Server – ceph-mon:
Diese Knoten speichern verschiedene Verwaltungsdaten (maps), z.B. für die Objektspeicher (OSD).
Es sollten mindestens drei Monitor-Server in einem Cluster vorhanden sein.
Manager-Server – ceph-mgr:
Diese Knoten verwalten den Zustand des Clusters und sammeln dazu Informationen von allen anderen Knoten.
Zur Visualisierung wird ein Dashboard und ein REST API bereitgestellt.
Es sollten mindestens zwei Manager-Server vorhanden sein.
Daten-Server .. ceph-osd:
OSD steht für „Object Storage Daemon“: hier werden die Daten physikalisch abgelegt und für die redundante Verteilung gesorgt.
Mindestens 3 OSD-Server werden für ein Cluster benögigt.
Metadaten-Server – ceph-mds:
Clients, die auf Ceph als POSIX file system zugreifen wollen, sind auf einen weiteren Server-Typ, den Metdaten-Server (MDS) angewiesen.
Aus Gründen der Verfügbarkeit sollte diese Server ebenfalls redundant ausgelegt sein.
Damit ergibt sich das folgende minimale Ceph-Cluster (hier noch ohne Metadaten-Server):
pic
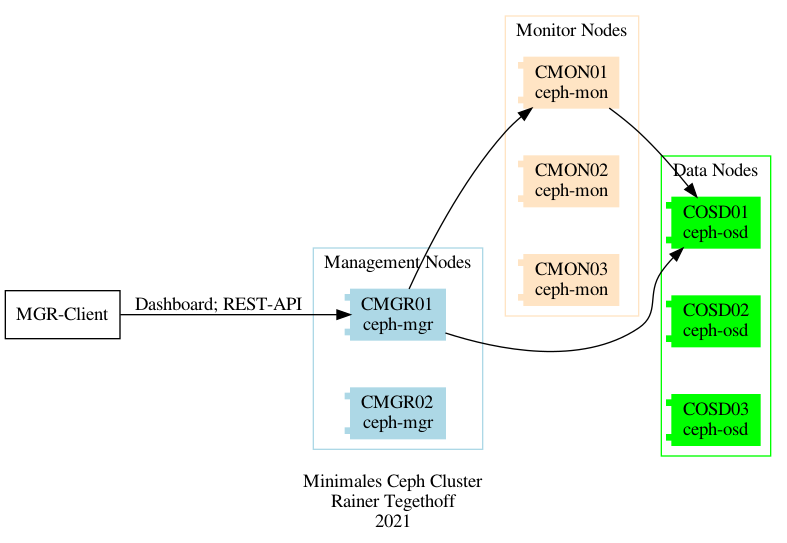
Falls die Clients nur Block- oder Object-Storage APIs nutzen ist das hinreichend.
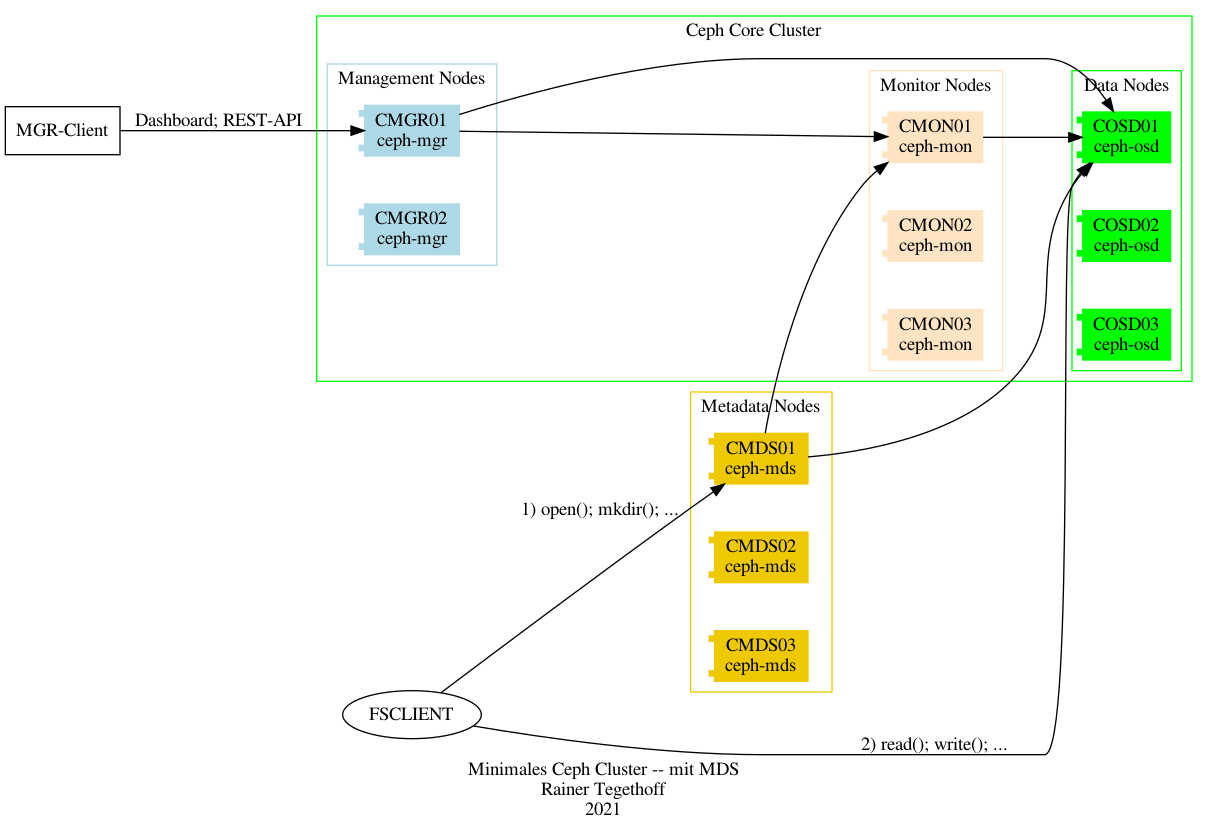
Für den Zugriff per POSIX Filesystem sind die MDS-Server mit einzuplanen.
Bemerkung
Die Verbindungen zwischen den MGR-Knoten und den MON-Knoten ist hier nur beispielhaft. Es soll zunächst nur deutlich werden, welche Komponenten in einem minimalen System gebraucht werden.
pic
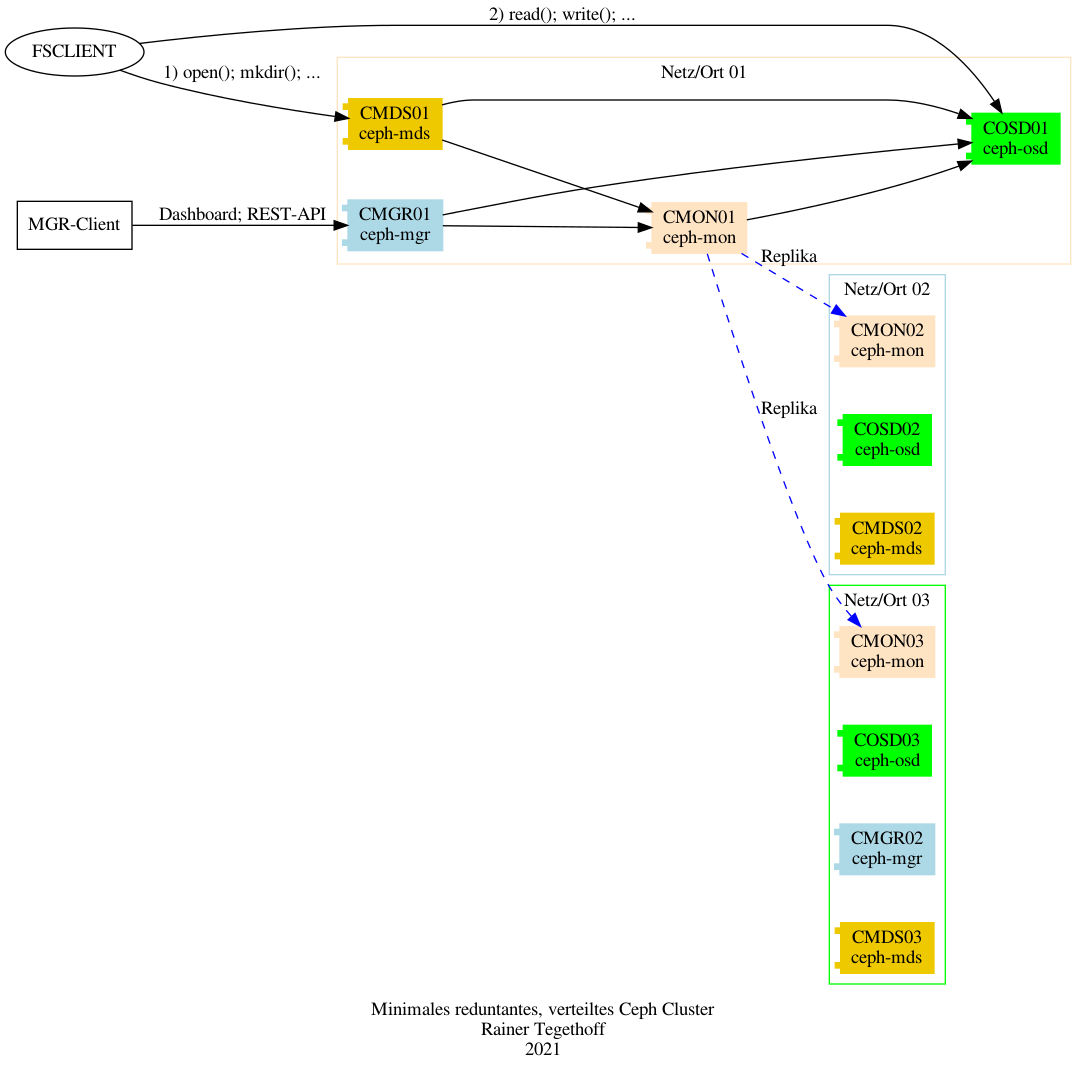
Redundante Server zu haben, um das System gegen einen Ausfall zu sichern, ist sicher notwendig. Allerdings sollten diese Server sich dann auch an verschiedenen Orten und/oder Netzen befinden damit nicht bei einem Stromausfall oder Brand beispielsweise alle Monitor-Server offline sind.
Deshalb werden im nächsten Entwurf die Server-Knoten in drei „Domänen“ aufgeteilt, die jeweils eine Instanz des entsprechenden Server-Typs beinhalten.
pic
6.3.2. Virtuelle Testumgebung#
Für ein „Proof Of Concept“ (POC) ist mir der Kauf von 11-12 physikalischen Servern an dieser Stelle etwas zu aufwendig. Selbst ein Dutzend RaspberryPis würde hier nicht helfen, weil sie nicht die notwendigen Voraussetzunge erfüllen.
Deshalb wurden für diesen Test „Sparmaßnahmen“ eingeführt:
Es werden nur drei Server eingerichtet.
Jeder dieser Server/Knoten hat mehrere Funktionen (MON, MGR, OSD, MDS).
Es handelt sich nicht um „echte“ physikalische Server (bar metal) sondern um Virtuelle Maschinen unter KVM.
Warnung
Das sollte man natürlich produktiv nie so machen.
Die Architektur vereinfacht sich damit wie folgt:
pic
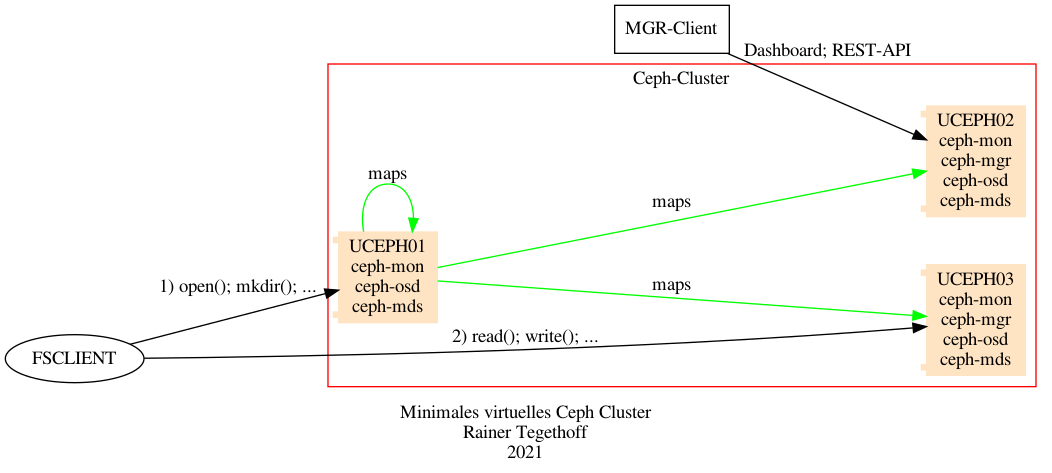
Damit sind zwar alle notwendigen Knoten-Typen vorhanden für den Betrieb eines Test-Clusters, aber es ist noch kein Speicher verfügbar, den die OSDs verwalten könnten.
Wir müssen den OSD-Knoten noch ein paar Festplatten/SSDs oder dergleichen spendieren. Das wird hier im Testsystem auf (natürlich) virtuellen SCSI-Disks geschehen.
Damit rundet sich das Bild:
pic
6.4. Aufsetzen der VMs#
Bei dem Betriebssystem für die Ceph-Nodes habe ich mich für Ubuntu/20 (Groovy) entschieden. Debian/10 (Buster) liess sich installieren aber die Nodes starteten nach einem shutdown nicht mehr komplett.
Um die Vervielfachung der virtuellen Ceph-Nodes zu vereinfachen, wird zunächst eine allgemeine VM „uref“ (Ubuntu Referenz) angelegt- Unter der Annahme, daß unter <PATH>/ubuntu-20.10-live-server-amd64.iso das entsprechnde ISO-image lieft, kann das wie folgt durchgeführt werden
virt-install --virt-type kvm --name uref --memory 2048 \
--cdrom <PATH>/ubuntu-20.10-live-server-amd64.iso \
--disk path=<VMPATH>/uref,size=12,bus=virtio,format=qcow2 \
--network=default,model=virtio \
--graphics spice \
--vcpus=2 \
--os-variant ubuntu19.04
Die Variablen <PATH> und <VMPATH> sind lokal festzulgen. Die OS-Variante war die jüngste bekannte Ubuntu-Version
osinfo-query os | grep -i ubuntu
Beim Einrichten (Boot) der VM ist darauf zu achten, dass ssh „enabled“ wird.
An dieser Stelle sind schon ein paar Vorkehrungen in Bezug auf das Vorgehen bei der CEPH-Installation zu treffen.
Es ist geplant CEPH 15.x (Octopus) zu installieren, und zwar mit dem neuen Tool cephadm. Ein wesentlicher Grund für diese Entscheidung ist das neue Dashboard, das damit bereit steht.
Damit mit cephadm eine Cluster ausgerollt werden kann, braucht jeder Knoten/Server einige Standard-Komponenten:
Python 3
Systemd
Podman oder Docker
chrony oder NTP
LVM2
Es macht daher Sinn diese Pakte schon bei der Knoten-Referenz zu installieren
% sudo apt-get update
% sudo apt-get install ntp
Falls an dieser Stelle für die Referenz-Maschin etwas fehlt, kann man das leicht auch per Ansible wieder ins Lot bringen mit einem kleinen Playbook:
- hosts: ceph become: True become_user: root become_method: sudo tasks: # zur Erinnerung - name: Ceph Voraussetzungen apt: update_cache: true cache_valid_time: 3600 pkg: ['ntp', 'lvm2']
Sicherheitshalber wird diese VM ge-cloned, um gegebenfalls auf eine valide Basis zurückkehren zu können
sudo virt-clone --original uref --name ucephref --auto-clone
Weitere Anpassungen werden auf dem Klone ucephref vorgenommen.
6.4.1. Cephadm auf Referenz#
Ab diesem Zeitpunkt wird das Vorhandensein einer VM ucephref mit Ubuntu-Groovy vorausgesetzt.
Ceph wird mit dem neuen cephadm installiert. Ein Rook-Deployment ist das Mittel der Wahl für ein Ceph-Cluster unter Kubernetes.
Andere Methoden werden hier zunächst nicht betrachtet und/oder sind etwas obsolet:
ceph-ansible : Mit dieses Lösung ist das neue Dashboard nicht verfügbar.
ceph-deploy : Diese Installationssoftware wird nicht mehr aktiv gewartet.
ceph-salt
jaas.ai/ceph-mon
github.com/openstack/puppet-ceph
Die einfachste Möglichkeit cepahadm auf die Referenzmaschine zu bekommen ist die Standard-Methode
# apt install -y cephadm
Um später das Kommado ceph nuten zu können sollte auch das Paket ceph-common installiert werden
# cephadm install ceph-common
6.4.2. Ceph Nodes / Clone#
Mit der neuen Vorlage, die auch cephadm enthält, lassen sich leich drei Kopien herstellen
# virt-clone --original ucephref --name uceph01 --auto-clone
# virt-clone --original ucephref --name uceph02 --auto-clone
# virt-clone --original ucephref --name uceph03 --auto-clone
Die Kopien sind zunächst zu 100% identisch zur Vorlage und damit auch die hostname. Das sollte umgehend (lokal) in der jeweiligen VM angepasst werden.
Für einen deterministischen Betrieb sollten die IP-Adressen der Clone-Nodes als feste IPs festgelegt werden. Die Nitzkonfiguration läßt sich leich mit dem virsh-Kommando anpassen:
Welche Netzwerke sind definiert
# virsh net-list Name State Autostart Persistent ------------------------------------------------- default active yes yes minikube-net active yes yesDie Anpassung erfolgt im „default“-Netz indem die aktuelle Konfiguration als XML-Datei exportiert wird, und wieder importiert wird
# virsh net-dumpxml default > net.xml # vi net.xml .... grep uceph01 net.xml <host mac='52:54:00:25:45:a5' name='uceph01' ip='192.168.122.165'/> # virsh net-define --file net.xmlWarnung
Das Vorgehen an dieser Stelle soll nur den Weg zeigen und ist nicht ganz vollständig.
Setzt man dieses Vorgehen für alle drei Kopien um und synchronisiert die lokale /etc/hosts mit den entsprechenden in den VMs, entwickelt sich ein konsistentes Netzwerk als Basis für ein Ceph-Cluster, das auch nach einem Neustart der VMs sich wieder identisch darstellt
(base) teg@nordri:/home/teg
> ping -c 1 uceph01
PING uceph01 (192.168.122.165) 56(84) bytes of data.
64 bytes from uceph01 (192.168.122.165): icmp_seq=1 ttl=64 time=0.249 ms
(base) teg@nordri:/home/teg
> ping -c 1 uceph02
PING uceph02 (192.168.122.166) 56(84) bytes of data.
64 bytes from uceph02 (192.168.122.166): icmp_seq=1 ttl=64 time=0.107 ms
(base) teg@nordri:/home/teg
> ping -c 1 uceph03
PING uceph03 (192.168.122.167) 56(84) bytes of data.
64 bytes from uceph03 (192.168.122.167): icmp_seq=1 ttl=64 time=0.359 ms
6.5. Ein neues Ceph Cluster#
Nachdem die Basis-Hardware vorhanden ist (drei Ubuntu VMs) können wir mit dem Ausrollen des Ceph-Clusters beginnen.
6.5.1. Master Node#
Es ist zunächst ein „Monitor-Server“ (siehe die verschiedenen Knotentypen) einzurichten. Dazu muß die IP-Adresse dieses Servers bekannt sein und für alle weiteren Konten im Netz erreichbar sein. In unserem Beispiel hat uceph01 mit der IP-Adresse 192.168.122.165 diese Aufgabe.
Zunächst ist auf ucpeh01 das Konifgurations-Verzfeichnis zu erstellen:
# mkdir -p /etc/ceph
Anschließend wird alles Notwendige per cephadm installiert
root@uceph01:/tmp# cephadm bootstrap --mon-ip 192.168.122.165
INFO:cephadm:Verifying podman|docker is present...
INFO:cephadm:Verifying lvm2 is present...
INFO:cephadm:Verifying time synchronization is in place...
INFO:cephadm:Unit systemd-timesyncd.service is enabled and running
INFO:cephadm:Repeating the final host check...
INFO:cephadm:podman|docker (/usr/bin/docker) is present
...
URL: https://uceph01:8443/
User: admin
Password: x6ezemc5hq
INFO:cephadm:You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid 24578ab8-409b-11eb-8ee0-81bee34a8684 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
INFO:cephadm:Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
INFO:cephadm:Bootstrap complete.
Diese Ersteinrichtung bewirkt Folgendes:
Es wird ein Monitor- und ein Manager Daemon eingerichtet.
Warnung
Das wird realisiert durch den Download und Adaption von Docker images und ist entsprechend Zeit-aufwendig!
Man findet anschließend folgende Docker images vor
root@uceph01:/tmp# docker images REPOSITORY TAG IMAGE ID CREATED SIZE ceph/ceph v15 2bc420ddb175 2 weeks ago 954MB ceph/ceph-grafana 6.6.2 a0dce381714a 6 months ago 509MB prom/prometheus v2.18.1 de242295e225 7 months ago 140MB prom/alertmanager v0.20.0 0881eb8f169f 12 months ago 52.1MB prom/node-exporter v0.18.1 e5a616e4b9cf 18 months ago 22.9MBEs wird ein SSH key für den Cluster erstellt unter /root/.ssh/authorized_keys .
Eine minimale Konfiguration wird geschrieben in /etc/ceph/ceph.conf .
Es wird ein administrativer Schlüssel für Clients erstellt unter /etc/ceph/ceph.client.admin.keyring .
Eine Kopie des öffentlichen Schlüssel wird kopiert nach /etc/ceph/ceph.pub .
Eine kleine Kontrolle zeigt, ob der neue Daemon läuft
root@uceph01:~# ceph -v
ceph version 15.2.7 (88e41c6c49beb18add4fdb6b4326ca466d931db8) octopus (stable)
root@uceph01:~# ceph status
cluster:
id: 24578ab8-409b-11eb-8ee0-81bee34a8684
health: HEALTH_WARN
mon uceph01 is low on available space
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum uceph01 (age 12m)
mgr: uceph01.ntrsho(active, since 12m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
6.5.2. Weitere Nodes#
Sobald der initiale Monitor-Node läuft, lassen sich weitere Nodes in unser Cluster einbringen. Es sollen also als nächstes die beiden VMs :
uceph02
uceph03
als Cluster-Knoten aufgenommen werden.
Dazu bedarf es zweier Schritte:
Der public ssh-key muss (als root) auf den neuen Knoten kopiert werden.
Warnung
Dazu muss root sich per ssh anmelden können und es ist eventuell ein entsprechender Eintrag in /etc/ssh/sshd_config notwendig.
Der neue Knoten muss im Cluster bekannt gemacht werden.
In unserem Test-Labor lässt sich das wie folgt realisieren:
SSH public keys übertragen
ssh-copy-id -f -i /etc/ceph/ceph.pub root@uceph02 ssh-copy-id -f -i /etc/ceph/ceph.pub root@uceph03Neue Knoten bekann machen
root@uceph01:~# ceph orch host add uceph02 Added host 'uceph02' root@uceph01:~# ceph orch host add uceph03 Added host 'uceph03'
Das Ergebnis läßt sich auch im Dashboard ablesen – drei Hosts sind jetzt im Cluster bekannt:
pic
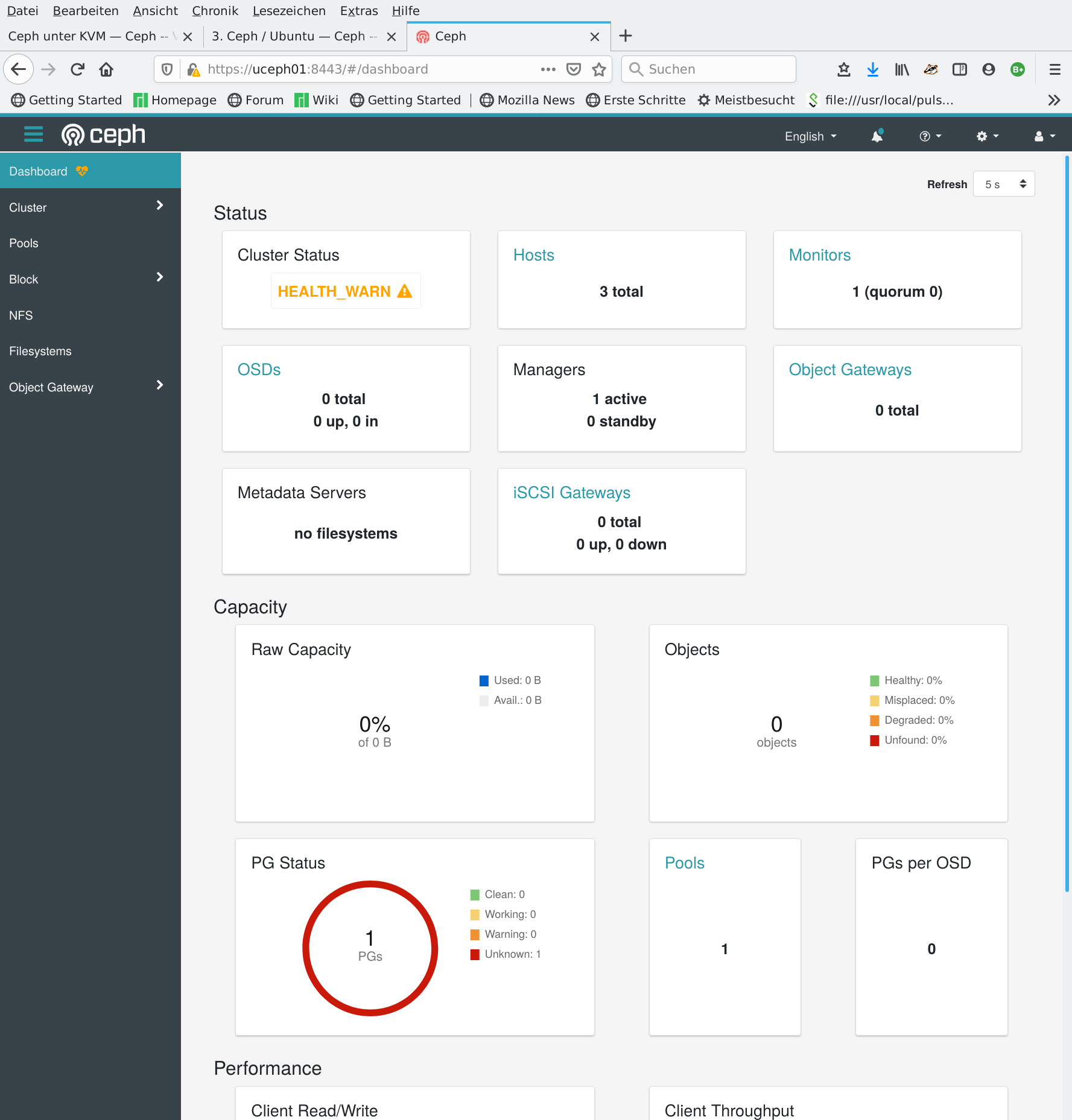
Es ist aber auch ersichtlich, daß unser Ceph-Cluster noch keinen Specher zur Verfügung stellen kann – kein Objekt- oder Blockspeicher und auch kein Filesystem.
Es fehlen uns schlicht ein paar Festplatten an unseren Cluster-Knoten für diesen Zweck.
6.5.3. Virtuelle Disks#
Um Ceph-Clients Speicherplatz anbieten zu können, benötigen die Ceph-Knoten entsprechende Ressourcen.
Für unseren Test sollen die Node-Server virtualle Festplatten erhalten. Dazu sind drei Schritte erforderlich:
Es wird eine leere Image-Datei mit dd angelegt, z.B. die Datei disk_uceph01_001.img
dd if=/dev/zero of=disk_uceph01_001.img bs=10M count=1024Es wird zur Konfiguration ein XML-File erstellt:
<disk type='file' device='disk'> <driver name='qemu' type='raw'/> <source file='<path>/disk_uceph01_001.img'/> <target dev='sdac' bus='scsi'/> <address type='drive' controller='4' bus='0' target='0' unit='0'/> </disk><path> ist entsprechend der Ablage zu setzen.
Der Device-Name (sdac) und der unit-counter sind zu inkrementieren.
Mit dem XML-File wird wird die virtuelle Disk an ein VM gebunden
virsh attach-device --config uceph01 ./disk_uceph01_001.xml
In der Gegenprobe müssen diese Disks jetzt sowohl im Cluster-Node auftauchen als auch in der Ceph-Orchestrierung.
Die Probe auf dem Node uceph01 aus der Perspektive des Betriebssystems
root@uceph01:~# fdisk -l | grep dev | grep sd
Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
Disk /dev/sda: 10 GiB, 10737418240 bytes, 20971520 sectors
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
Als Ceph Monitor werden die Disks ebenso gefunden
root@uceph01:~# ceph orch device ls
Hostname Path Type Serial Size Health Ident Fault Available
uceph01 /dev/sda hdd drive-scsi4-0-0 10.7G Unknown N/A N/A Yes
uceph01 /dev/sdb hdd drive-scsi4-0-1 10.7G Unknown N/A N/A Yes
uceph01 /dev/sdc hdd drive-scsi4-0-2 10.7G Unknown N/A N/A Yes
uceph02 /dev/sda hdd drive-scsi4-0-0 10.7G Unknown N/A N/A Yes
uceph02 /dev/sdb hdd drive-scsi4-0-1 10.7G Unknown N/A N/A Yes
uceph02 /dev/sdc hdd drive-scsi4-0-2 10.7G Unknown N/A N/A Yes
uceph03 /dev/sda hdd drive-scsi4-0-0 10.7G Unknown N/A N/A Yes
uceph03 /dev/sdb hdd drive-scsi4-0-1 10.7G Unknown N/A N/A Yes
uceph03 /dev/sdc hdd drive-scsi4-0-2 10.7G Unknown N/A N/A Yes
6.6. OSDs#
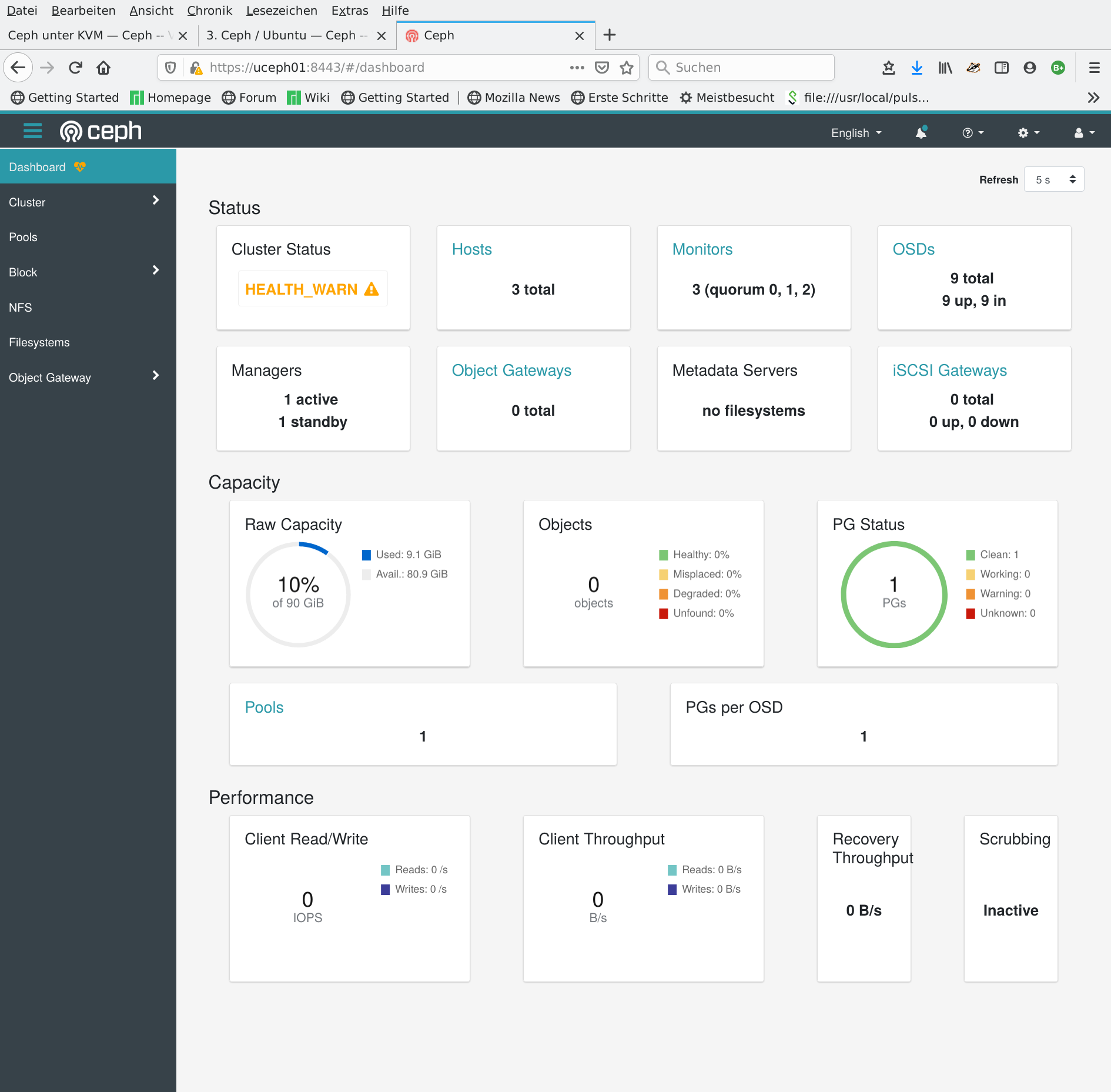
Nach der Bereitstellung der Disks können die „Object Storage Daemons“ eingerichtet werden, Beispielsweise werden die OSDs für den Disk-Server useph03 vom Monitor-Server uceph01 wie folgt erstellt
root@uceph01:~# ceph orch daemon add osd uceph03:/dev/sda
Created osd(s) 6 on host 'uceph03'
root@uceph01:~# ceph orch daemon add osd uceph03:/dev/sdb
Created osd(s) 7 on host 'uceph03'
root@uceph01:~# ceph orch daemon add osd uceph03:/dev/sdc
Created osd(s) 8 on host 'uceph03'
Wenn nach diesem Schema alle drei Nodes je Disk einen OSD bekommen haben, lässt sich das Ergebnis wieder hübsch im Dashboard verfolgen:
6.7. MDS#
Wie eingangs schon erwähnt, werden zwingend noch weitere Server, nämlich Meta-Daten-Server gebraucht, um eine POSIX kompatibles Dateisystem bereitstellen zu können.
Wir werden die beiden Nodes ucpeh02 und uceph03 deshalb auch noch als MDS einrichten
ceph orch apply mds cfs_one --placement="2 uceph02 uceph03"
Jetzt haben sie alle notwendigen Nodes mit entsprechenden Server-Typ erstellt. Um den Überblick zu behalten hilft an dieser Stelle wieder das Dashboard:
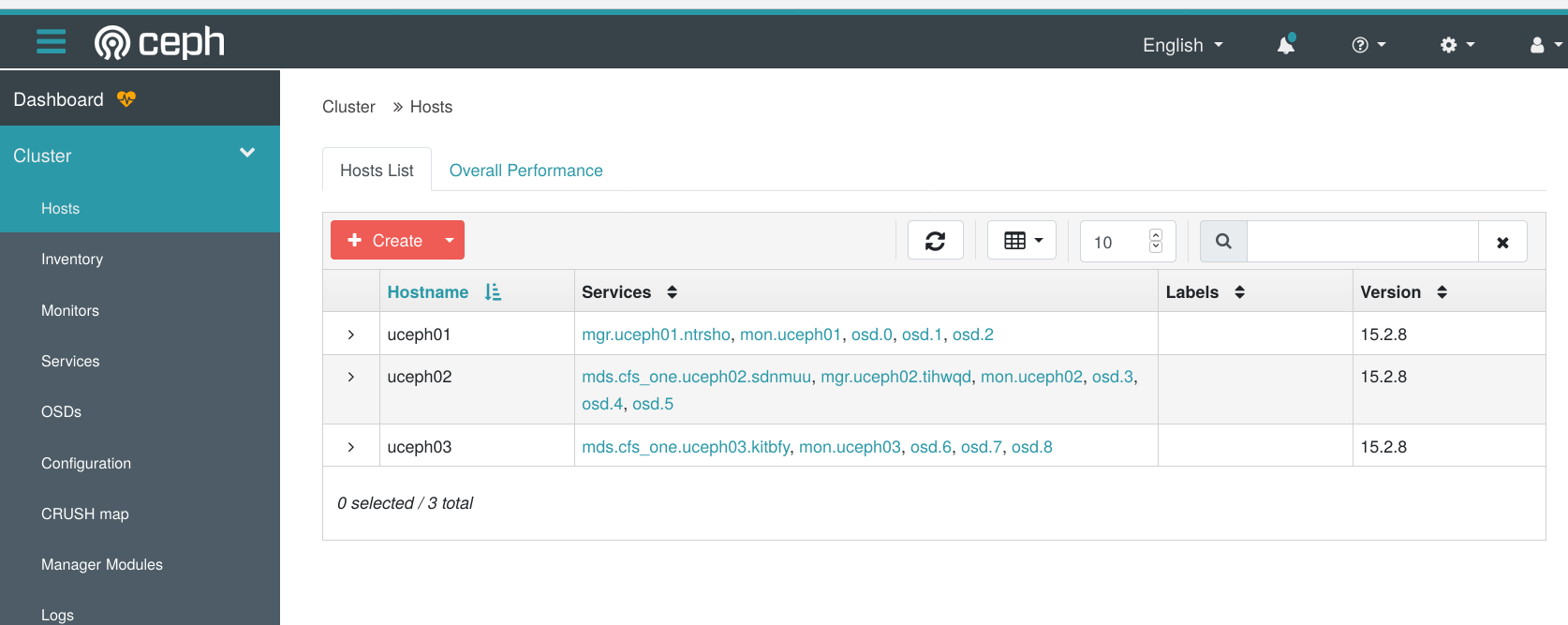
Es sind tatsächlich alle Spielarten vertreten und dazu noch redundant:
Monitor – mon
Manager – mgr
Object-Storage – ods
Meta-Data-Server – mds
6.8. Ceph FS Server#
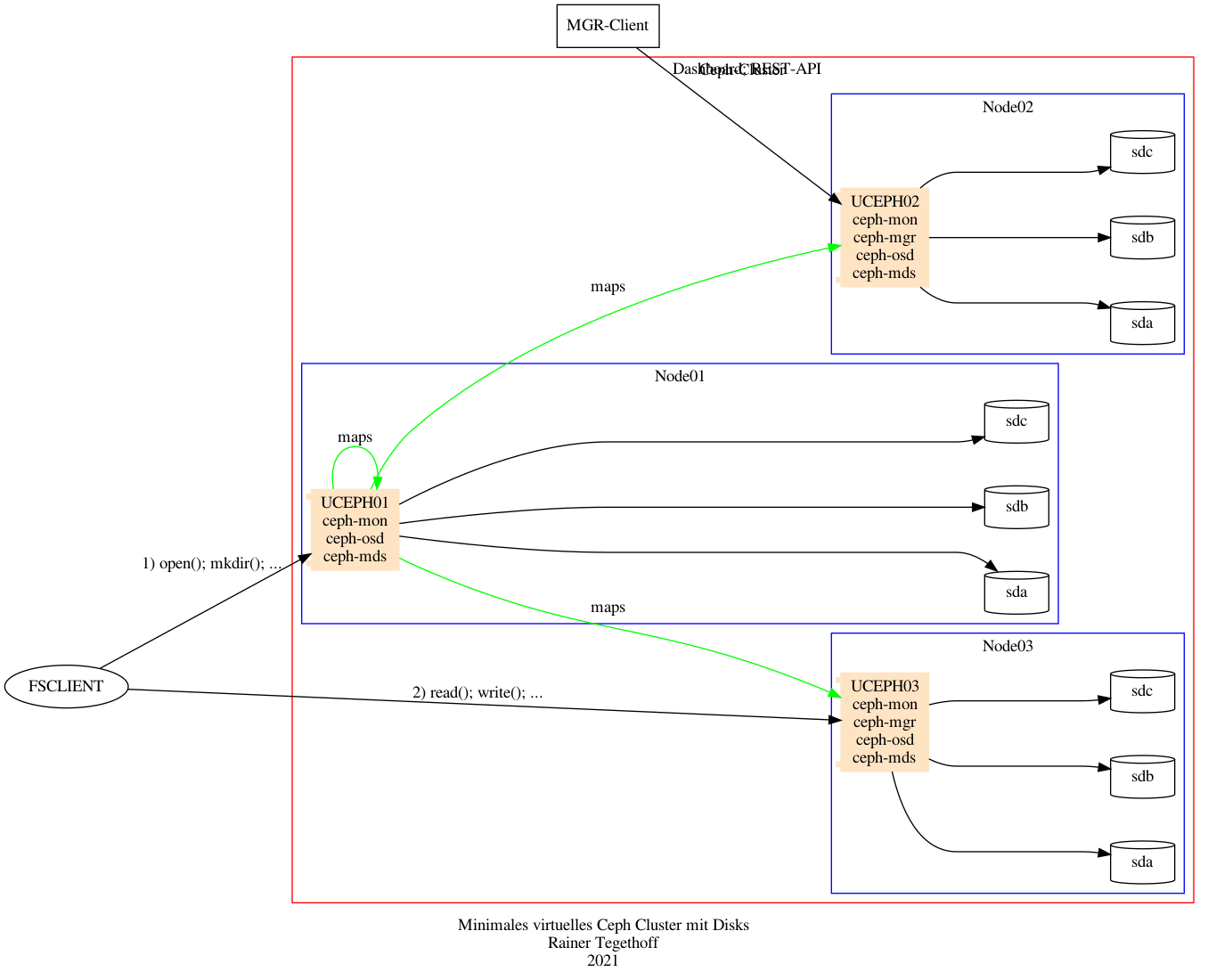
Das Ceph File System (CephFS) setzt auf Cephs Object-Storage (RADOS) auf. Es werden dabei zwei getrennte „Töpfe“ angeleget: eine „Data Pool“ und ein „Metadata Pool“.
Der Metadaten-Pool wird von den MDS-Nodes beschrieben. Der Daten-Pool direkt von den Clients.
Das folgende Bild zeigt die Architektur:

Ceph verspricht an dieser Stelle, dass damit das Gesamtsystem linea skaliert mit dem Anwachsen des Objekt-Speichers (RADOS) und der Nodes.
Soweit zur Theorie. Im Praxisbeispiel legen wir die Poolss und ein CepfFS wie folgt an:
Pools
root@uceph01:~# ceph osd pool create cephfs_data pool 'cephfs_data' created root@uceph01:~# ceph osd pool create cephfs_metadata pool 'cephfs_metadata' createdFile-System
root@uceph01:~# ceph fs new cfs_one cephfs_metadata cephfs_data new fs with metadata pool 3 and data pool 2 root@uceph01:~# ceph fs ls name: cfs_one, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
6.9. CepfFS Client Mount#
Obwohl CepfFS Cleint-seitig seit ca. 2009 (Kernel 2.6.33) im Linux Kernel integriert ist [2] und entsprechend aktuell bei kernel.org dokumentiert ist [3] bedarf es für das Test-Environment noch einiger kleiner Vorbereitungen:
Der Client braucht ein Verzeichnis für Konfigurationsdaten und Schlüssel.
Die minimale Konfiguration und der Schlüssel muss vom Monitor-Node auf den Cleint kopiert werden.
Eine lokaler mount point muss eingerichtet sein.
Ergo ergeben sich folgende Arbeitsschritte
# cd /etc/ceph
# scp root@uceph01:/etc/ceph/ceph.client.admin.keyring .
# scp root@uceph01:/etc/ceph/ceph.conf .
# mkdir /mnt/cfs
Nun bleibt nur der finale Schritt – mount das File-System
# mount -t ceph uceph02:6789:/ /mnt/cfs -o name=admin
So einfach: am Ende dieses kleinen Experiments haben wir einige GB Speicherplatz auf einem Filesystem zu Verfügung, dass das Potential für ExaByte hat – alles nur eine Frage der Hardware, die im „Proof of Concept“ natürlich etwas beschränkt ist
$ df -hT | grep -E "cfs|Used"
Filesystem Type Size Used Avail Use% Mounted on
192.168.122.166:6789:/ ceph 37G 6.9G 30G 20% /mnt/cfs
6.10. Referenzen#
Referencen
URLs
Footnotes