2. Python / DEA – vCard Reader#
In diesem Kapitel wird die Konvertierung einer VCF-Datei in CSV und zurück mittels eine „Deterministischen Endlichen Automaten“ (DEA) vorgestellt.
2.1. So geht’s: VCF -> CSV#
Bemerkung
Der Konverter ist ein Python-Programm, dass in einer „shell“ ausgeführt wird.
Die einzelnen Schritte.
Exportiere die Kontaktdaten des Smartphones in eine VCF-Datei, z.B.:
phone.vcf
Erstelle aus phone.vcf eine Datei im CSV-Format, dass man mit Libreoffice oder Excel öffnen und bearbeiten kann
$ vcf2csv.py --vcf_datei data/phone.vcf result: report.d/csv_ausgabe.csv
Bemerkung
Duplikate sind in der Ausgabe entfernt worden.
Erstelle sicherheitshalber eine Arbeitskopie
cp report.d/csv_ausgabe.csv phone_neu.csv
Bearbeite die Arbeitskopie phone_neu.csv mit Libreoffice oder Excel.
Erstelle aus der CSV-Datei eine neue VCF-Datei mit korrigierten Daten für den Import im neuen Smartphone oder per Thunderbird.
$ ./csv2vcf.py --csv_datei report.d/phone_neu.csv result: report.d/vcf_ausgabe.vcf
Importiere die neue, überarbeitete VCF-Datei vcf_ausgabe.vcf.
Bemerkung
Das Programm vcf2csv.py verarbeitet auf meinem Rechner 4000 Zeilen VCF in 0,1 Sekunden.
2.2. Motivation#
Im Oktober 2020
Nach vielen Jahren der Nutzung war der Zeitpunkt gekommen, dass mein Smartphone „HTC One“ ausgedient hatte und ich nur noch die Kontakte retten wollte, um selbige in Thunderbird zu importieren.
Eine geradezu banale Aufgabe:
Exportiere die Kontakte (in das VCF Format).
Importiere mit dem Thunderbird „Adressbook-Tool“ die Export-Datei.
Das „HTC One“ exportiert aber nur verschlüssel in „VEF“. Als „workaround“ wurden die Kontakte via:
„Speichern in Google“
Export nach VCF
dann doch noch in dieses Universalformat überführt.
Der Export der Kontaktdaten ist gelungen.
Der Import ist „eigentlich“ auch ganz einfach mit Thunderbird
[Tools]
Adressbook
[Tools]
Import
Allerdings war das Ergebnis etwas ernüchternd:
Die Hälfte aller Adressen waren Duplikate.
Viele Telefon-Nummern wurden nicht übernommen.
VCF-Dateien sind zwar einfache Textdateien und damit mit jedem entsprechenden Editor bearbeitbar, aber die Zeilen-Struktur macht die Bearbeitung umständlich.
Viel schöner wäre es, die Adressen in Excel oder Libreoffice in einem Spreadsheet zu bearbeiten!
2.2.1. Aufgabe#
Konvertiere eine VCF-Datei in das CSV-Format, so dass es von Libreoffice importiert werden kann.
Exportiere die CSV-Datei aus dem vorherigen Schritt in eine VCF-Datei, die „Thunderbird-kompatibel“ ist.
2.3. Simpler Endlicher-Automat#
Die VCF-Datei speichert für jede Adresse einige Datenzeilen, z.B.
BEGIN:VCARD
VERSION:2.1
N:Pannenhilfe;ADAC;;;
FN:ADAC Pannenhilfe
TEL;VOICE;PREF:+49172222222
CATEGORIES:My Contacts
END:VCARD
Offensichtlich gibt es 4 Datenfelder:
N:
Nachname, Vorname und mehr
FN:
„Fullname“
TEL
Telefon
CATEGORIES
Eine Kategorisierung
Insgesamt gibt es 7 Pattern, die den neuen Zustand einleiten
BEGIN:
VERSION:
N:
FN:
TEL;
CATEGORIES:
END
Bei den vorliegenden Daten war die Ausgabereihenfolge dieser Felder immer gleich, so dass man von einer vorgeschriebenen Reihenfolge ausgehen kann.
Mit den bisherigen Informationen und Annahmen scheint ein „Endlicher Automat“ (https://de.wikipedia.org/wiki/Endlicher_Automat) die geeignete Wahl zur sein, um eine derartige VCF-Datei einzulesen.
Der „Automat“, der zu obigen VCF-Daten, kann wir folgt aussehen:
pic

Eine Klasse, die den obigen Automaten implementiert, ist relativ schnell geschrieben:
Code-Exzerpt:
1 class CVcfEaA: 2 """ 3 Endicher Automat zum Abarbeiten einer VCF-Datei. 4 Der Automatenzustand wird über eine Lookahead-Zeile bestimmt. 5 Die Bearbeitung erfolgt auf der Zeile vor der Lookahead-Zeile. 6 """ 7 8 def __init__(self, vcf_list: list): 9 self.vcf_lst = vcf_list 10 self.line_nr = None 11 self.line = None 12 13 def _s00_start(self, line): 14 rvs = self._s_error 15 if line.startswith('BEGIN:'): 16 rvs = self._s01_begin 17 return rvs 18 19 def _s01_begin(self, line): 20 rvs = self._s_error 21 if line.startswith('VERSION:'): 22 rvs = self._s02_version 23 return rvs 24 25 def _s02_version(self, line): 26 rvs = self._s_error 27 if line.startswith('N:'): 28 rvs = self._s03_n 29 return rvs 30 31 def _s03_n(self, line): 32 rvs = self._s_error 33 if line.startswith('FN:'): 34 rvs = self._s04_fn 35 return rvs 36 37 def _s04_fn(self, line): 38 rvs = self._s_error 39 if line.startswith('TEL'): 40 rvs = self._s05_tel 41 return rvs 42 43 def _s05_tel(self, line): 44 rvs = self._s_error 45 if line.startswith('CATEGORIES:'): 46 rvs = self._s06_categories 47 return rvs 48 49 def _s06_categories(self, line): 50 rvs = self._s_error 51 if line.startswith('END:'): 52 rvs = self._s20_end 53 return rvs 54 55 def _s20_end(self, line): 56 rvs = self._s_error 57 if line.startswith('BEGIN:'): 58 rvs = self._s01_begin 59 return rvs 60 61 def _s_error(self, line): 62 emsg = f'{self.line_nr + 1}: {self.line}' 63 raise StateException(emsg) 64 65 def parce_vcf(self): 66 state = self._s00_start 67 for self.line_nr, self.line in enumerate(self.vcf_lst): 68 state = state(self.line)
Der „Automat“ funktioniert wie folgt:
Von einem Hauptprogramm wird die Klasse instanziiert mit einer Liste der Zeilen der VCF-Datei und die Methode parse_vcf (Zeile 65) wird aufgerufen, z.B.:
ea_parser = CVcfEaA(vcf_list=self.vcf_lst) ea_parser.parce_vcf()
In Zeile 66 wird der Start-Zustand gesetzt.
Der Zustandswechsel des Automaten erfolgt in Zeile 66 mit jeder neuen VCF-Zeile.
Jede Zustand-Methode liefert den Folgezustand auf Basis der gerade aktuellen Datenzeile. Für den Fall, dass der Zustandsübergang nicht nach Plan läuft, wird per default ein Fehlerstatus gesetzt, z.B.:
def _s04_fn(self, line): rvs = self._s_error if line.startswith('TEL'): rvs = self._s05_tel return rvs
2.3.1. Grenzen des Automaten#
Diese einfache und klare Realisierung des Formatwandlers stößt leider sehr schnell an seine Grenzen und zwar in meiner Ausgabe des HTC-Smartphones nach 6 verarbeiteten Zeilen
$ vcf2csv.py --vcf_datei data/phone.vcf
log file: /tmp/vcf2csv_2020-10-04.log
Traceback (most recent call last):
File "./vcf2csv.py", line 48, in <module>
vro.run()
File "./vcf2csv.py", line 43, in run
ea_parser.parce_vcf()
File "/Src/qlib/vcfea.py", line 169, in parce_vcf
state = state(self.line)
File "/Src/qlib/vcfea.py", line 164, in _s_error
raise StateException(emsg)
qlib.vcfea.StateException: 21: CATEGORIES:My Contacts
Im obigen Source-Code findet man in Zeile 63 den Trigger für die Exception. Anscheinend konnte in einem Zustand kein gültiger Folgezustand identifiziert werden und die Fehlerbehandlung wurde ausgelöst.
Die Ursache war einfach: die aktuelle Adresse hatte 2 Telefonnummern (2 Zeilen) eingetragen und der bisherige Automat kennt nur den Übergang von
Telefon -> Kategorie
Der Automat ist anscheinend nicht vollständig und muss überarbeitet werden.
2.4. Automat für HTC-VCF#
Die VCF-Datei, die es zu transformieren gilt, ist etwas komplexer als der erste Ansatz nahelegt.
Für jeden Zustand/Pattern ist zu überprüfen, was gültige Nachfolger sind.
Am Beispiel Telefon, kann das beispielsweise wie folgt geschehen
$ grep -A 1 "^TEL" data/teg_firma.vcf | grep -Ev "^TEL|\-\-" | sed 's/:.*/:/' | sort | uniq
CATEGORIES:
ORG:
Bemerkung
TEL ist auch ein Nachfolger. Dieses Pattern wird aber „weg-ge-grep-ed“!
Führt man diese Aktion für alle Pattern (Zeichenfolge, die den neuen Zustand festlegt) ergibt sich folgendes neues Zustandsübergangsdiagramm (die Pattern sind den Übergängen zugefügt):
pic
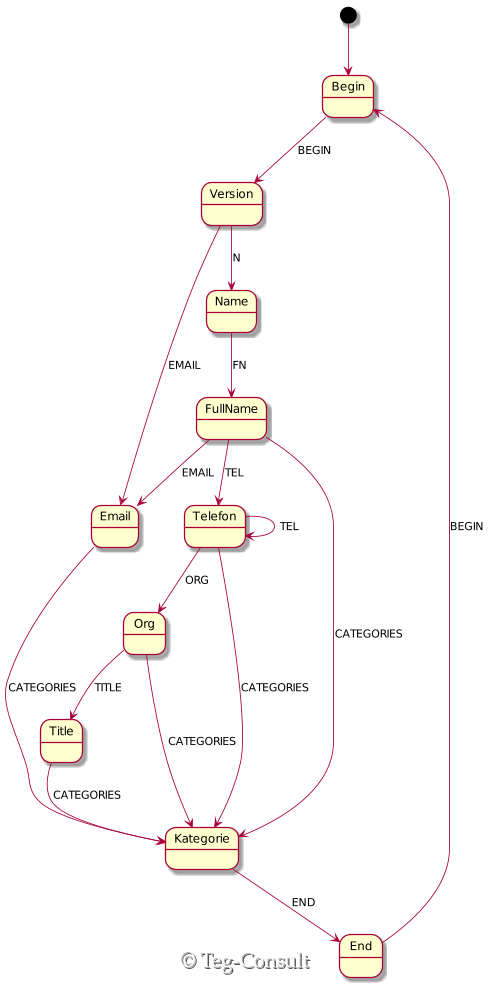
2.4.1. Zustand erkennen#
Die meisten Zustände haben mehre Übergänge. „Begin“ und „End“ sind aber gleich geblieben.
Der Source-Code wird deshalb aufgeteilt:
Ein allgemeiner Teil (abstrakte Klasse) die gleiche Teile implementiert.
1class CVcfEaBase(ABC): 2 """ 3 Endicher Automat zum Abarbeiten einer VCF-Datei. 4 Der Automatenzustand wird über eine Lookahead-Zeile bestimmt. 5 Die Bearbeitung erfolgt auf der Zeile vor der Lookahead-Zeile. 6 """ 7 8 def __init__(self, vcf_list: list): 9 self.log = get_logger() 10 self.vcf_lst = vcf_list 11 self.line_nr = None 12 self.line = None 13 self.work_line = None 14 self.work_adr = empty_vcf_in_adress() 15 self.adr_lst = [] 16 self.adr_hash = {} # key == CDcAdress.__repr__; value == CDcAdress 17 18 def _s00_start(self, line): 19 self.log.debug(f'{self.line_nr:6} {line}') 20 rvs = self._s_error 21 if line.startswith('BEGIN:'): 22 rvs = self._s01_begin 23 return rvs 24 25 def _s01_begin(self, line): 26 self.log.debug(f'{self.line_nr:6} {line}') 27 rvs = self._s_error 28 self.work_adr = empty_vcf_in_adress() 29 if line.startswith('VERSION:'): 30 rvs = self._s02_version 31 return rvs 32 33 @abstractmethod 34 def _s02_version(self, line): 35 pass 36 37 def _s20_end(self, line): 38 self.log.debug(f'{self.line_nr:6} {line}') 39 rvs = self._s_error 40 self.add_new_adress(self.work_adr) 41 if line.startswith('BEGIN:'): 42 rvs = self._s01_begin 43 return rvs 44 45 def _s_error(self, line): 46 emsg = f'{self.line_nr + 1}: {self.line}' 47 raise StateException(emsg) 48 49 def parce_vcf(self): 50 state = self._s00_start 51 for self.line_nr, self.line in enumerate(self.vcf_lst): 52 state = state(self.line) 53 self.work_line = self.line 54 state('FIN') 55 write_adresses_to_csv(self.adr_lst)
Ein variabler Teil (abgeleitete Klasse), die die unterschiedlichen Zustandsübergänge abbildet.
1class CVcfEaReader(CVcfEaBase): 2 """ 3 Endicher Automat zum Abarbeiten einer VCF-Datei. 4 Der Automatenzustand wird über eine Lookahead-Zeile bestimmt. 5 Die Bearbeitung erfolgt auf der Zeile vor der Lookahead-Zeile. 6 """ 7 8 def __init__(self, vcf_list: list): 9 super(CVcfEaReader, self).__init__(vcf_list=vcf_list) 10 11 def _s02_version(self, line): 12 self.log.debug(f'{self.line_nr:6} {line}') 13 rvs = self._s_error 14 if line.startswith('N'): 15 rvs = self._s03_n 16 elif line.startswith('EMAIL'): 17 rvs = self._s07_email 18 return rvs 19 20 def _s03_n(self, line): 21 self.log.debug(f'{self.line_nr:6} {line}') 22 rvs = self._s_error 23 if line.startswith('FN'): 24 # FN: or FN; 25 rvs = self._s04_fn 26 return rvs 27 28 def _s04_fn(self, line): 29 self.log.debug(f'{self.line_nr:6} {line}') 30 rvs = self._s_error 31 if line.startswith('TEL;'): 32 rvs = self._s05_tel 33 elif line.startswith('CATEGORIES:'): 34 rvs = self._s06_categories 35 elif line.startswith('EMAIL;'): 36 rvs = self._s07_email 37 return rvs
Dies ist ein Auszug für die Pattern „N:“ und „FN:“. Man sieht in den Zeilen 31-36 wie die Übergänge im obigen Diagramm 1:1 abgebiledet werden.
Die weiternen Methoden sind zur Übung.
2.4.2. Nutzdaten finden#
Bislang haben wir nur dafür gesorgt, dass unser „Automat“ immer im richtigen Zustand ist. Das eigentliche Ziel ist natürlich die Extraktion der Nutzdaten.
Als „Nebeneffekt“ zum Zustand haben wir eine aktuelle Datenzeile passend zum Zustand, beispielsweise zu „_n“
N:Pannenhilfe;ADAC;;;
Für jeden Datenzeiltyp/-zustand wird eine entsprechende Methode implementiert und in der Zustandsmethode aufgerufen:
1def _s03_n(self, line): 2 self.log.debug(f'{self.line_nr:6} {line}') 3 rvs = self._s_error 4 self._ac_name() 5 if line.startswith('FN'): 6 # FN: or FN; 7 rvs = self._s04_fn 8 return rvs 9 10def _s04_fn(self, line): 11 self.log.debug(f'{self.line_nr:6} {line}') 12 rvs = self._s_error 13 self._ac_fullname() 14 if line.startswith('TEL;'): 15 rvs = self._s05_tel 16 elif line.startswith('CATEGORIES:'): 17 rvs = self._s06_categories 18 elif line.startswith('EMAIL;'): 19 rvs = self._s07_email 20 return rvs
Im Beispiel findet man in Zeile 5 und Zeile 14 die Aufrufe.
Die Implementierung sieht wie folgt aus:
1def _ac_name(self): 2 # work_line example: N:Pannenhilfe;ADAC;;; 3 name = ' '.join(self.work_line[2:].split(';')).strip() 4 name = self._decode_name(name) 5 self.work_adr.name = name 6 7def _ac_fullname(self): 8 # work_line: FN:ADAC Pannenhilfe 9 self.work_adr.fullname = self._decode_name(self.work_line[3:])
Die Dateien einer vCard-Adresse werden in dem Objekt-Instanz self.work_adr gespeichert, die eine „dataclass“ ist:
1@dataclass 2class CDcCsvAdress: 3 name: str 4 fullname: str 5 mail: str 6 tel: list 7 org: str 8 title: str 9 cat: str 10 iflag: str 11 12 def __lt__(self, other): 13 return self.name < other.name
Weil alle Adressen in einer Liste gespeichert werden, können wir durch die Überladung des Operators „__lt__“ einfach eine Sortierung erzielen, z.B. in der Ausgabe-Methode:
1def write_adresses_to_csv(adr_lst: [CDcCsvAdress]): 2 """ 3 Schreibe die Adressen nach Namen sortiert in eine CSV-Datei 4 """ 5 with open(str(VCF_OUT_PATH), 'wt') as ofh: 6 wo = DictWriter(ofh, fieldnames=get_vcf_in_adress_keys(), 7 delimiter=',', quotechar='"', quoting=QUOTE_ALL) 8 wo.writeheader() 9 for ado in sorted(adr_lst): 10 # konvertiere Telefon-Liste in string mit '|' getrennt 11 tel_str = TEL_DELIMITER.join(ado.tel) 12 ado.tel = tel_str 13 wo.writerow(asdict(ado))
2.5. HTC CSV Format#
Nach dem Einlesen soll jeder vCard-Datensatz als eine Zeile (Record) in einer CSV-Datei ausgegeben werden. Die CSV-Datei stellt also gewissermaßen eine Mine-Datenbank dar und wir müssen die Felder/Attribute jeder Zeile noch festlegen.
Jede Zeile soll alle möglichen Entitäten unser bisherigen Adressen enthalten
name fullname mail tel org title cat iflag
Die Namen entsprechen weitestgehend denen der vCard-Definitionen. Neu ist das iflag: das Import-Flag ist ein boolscher Wert, über den man später den Import steuern kann (t == True: der Datensatz soll importiert werden).
Es bleibt noch ein kleines Problem: eine Adresse kann mehrere Telefone haben. In der Spalte „tel“ werden verschieden Telefonnummern zusammengefasst und durch das Zeichen „|“ getrennt, z.B.
+49304711|+494232168
Damit ist die erste Version der Ausgabe fertig. Ein Beispiel zeigt das Ergebnis
$ vcf2csv.py --vcf_datei data/phone.vcf
result: report.d/csv_ausgabe.csv
$ grep -E "full|ADAC" report.d/csv_ausgabe.csv
"name","fullname","mail","tel","org","title","cat","iflag"
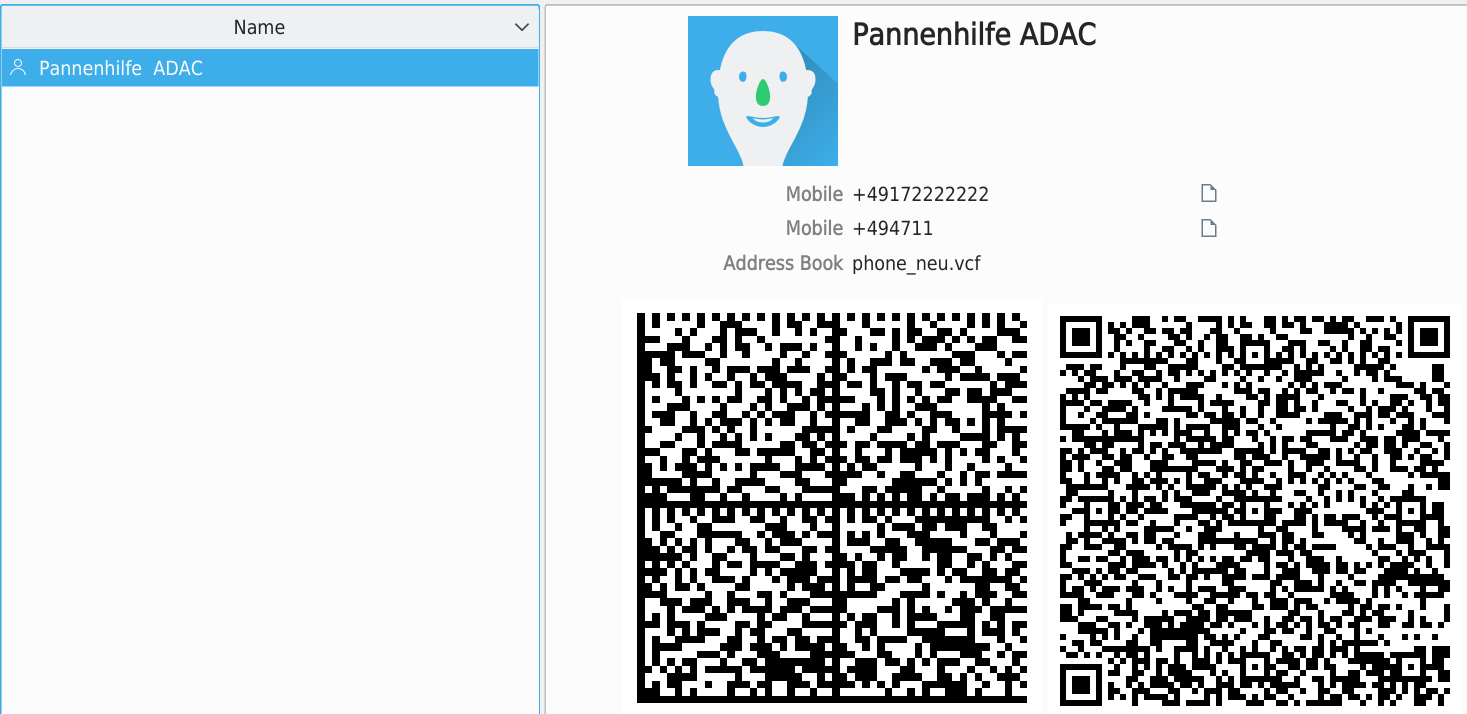
"Pannenhilfe ADAC","ADAC Pannenhilfe","","+49172222222","","","Work","t"
Fertig.
Oder doch nicht?
Bislang wurde noch nicht sichergestellt, ob das was wir hier in die CSV-Datei schreiben auch von Thunderbird gelesen werden kann.
Erinnern wir uns: es gab zwei Gründe die VCF-Datei nicht direkt zu importieren:
Es sollten die vielen Duplikate entfernt werden.
Das wurde erreicht mit der Umwandlung nach CSV.
Die Ausgabe solle „einfach“ nacharbeitbar sein.
Auch dieses Ziel wurde erreicht.
2.6. CSV -> VCF#
Mit dem Vorliegen einer „sauberen“ CSV-Datei kann eine ebenso blitzblanke VCF-Datei geschrieben werden, die dann beispielsweise vom Mail-Client eingelesen werden kann.
D.h. der Arbeitsablauf ist wie folgt:
Original HTC-Ausgabe nach CSV konvertieren
$ vcf2csv.py --vcf_datei data/phone.vcf result: report.d/csv_ausgabe.csv
Erstelle eine Arbeitskopie
cp report.d/csv_ausgabe.csv report.d/phone_neu.csv
Editiere report.d/phone_neu.csv.
Konvertiere diese abgespeckte CSV-Datei wieder nach VCF
$ ./csv2vcf.py --csv_datei report.d/phone_neu.csv result: report.d/vcf_ausgabe.vcf
Importiere report.d/vcf_ausgabe.vcf.
2.7. Am Ziel#
Die neue VCF-Datei aus dem letzten Kapitel wurde dann in KAdressBook und Thunderbird importiert.
Dabei zeigte Thunderbird zwei Schwächen, die KAdressBook nicht kennt:
Bei Adressen mit mehreren Telefonnummern wurde nur eine Übernommen
BEGIN:VCARD VERSION:2.1 N:ADAC;Pannenhilfe;;; FN:Pannenhilfe ADAC TEL;CELL:+49172222222 TEL;CELL:+494711 CATEGORIES:Work END:VCARD
Die VCF-Ausgabe ist UTF-8 codiert geschrieben. Die wurden in Thunderbird nicht korrekt dargestellt.
Eine importierte Adresse in KAdressBook:
pic