3. Python / ANTLR – vCard Reader#
In diesem Kapitel wird die Konvertierung einer VCF-Datei in CSV und zurück mittels eines Compiler-Tools (ANTLR) vorgestellt.
- ANTLR (ANother Tool for Language Recognition) is a powerful parser generator
for reading, processing, executing, or translating structured text or binary files. It’s widely used to build languages, tools, and frameworks. From a grammar, ANTLR generates a parser that can build and walk parse trees. (https://www.antlr.org/)
3.1. So geht’s#
Bemerkung
Der Konverter ist ein Python-Programm, dass in einer „shell“ ausgeführt wird.
Das „User-Interface“ ändert sich also nicht zum vorherigen Kapitel und damit auch nicht die Nutzung.
Die einzelnen Schritte.
Exportiere die Kontaktdaten des Smartphones in eine VCF-Datei, z.B.:
phone.vcf
Erstelle aus phone.vcf eine Datei im CSV-Format, dass man mit Libreoffice oder Excel öffnen und bearbeiten kann
$ vcf2csv.py --vcf_datei data/phone.vcf result: report.d/csv_ausgabe.csv
Bemerkung
Duplikate sind in der Ausgabe entfernt worden.
Erstelle sicherheitshalber eine Arbeitskopie
cp report.d/csv_ausgabe.csv phone_neu.csv
Bearbeite die Arbeitskopie phone_neu.csv mit Libreoffice oder Excel.
Erstelle aus der CSV-Datei eine neue VCV-Datei mit korrigierten Daten für den Import im neuen Smartphone oder per Thunderbird.
$ ./csv2vcf.py --csv_datei report.d/phone_neu.csv result: report.d/vcf_ausgabe.vcf
Importiere die neue, überarbeitete VCF-Datei vcf_ausgabe.vcf.
3.2. Wofür der Mehraufwand#
Die VCF -> CSV -> VCF Konvertierung wurde im letzten Kapitel erfolgreich implementiert.
Warnung
Die Implementierung per DEA stellt faktisch nur eine kleine Teilmenge des wirklichen Umfangs dar.
Ein Blick auf Wikipedia zeigt uns fehlende Funktionalitäten (https://de.wikipedia.org/wiki/VCard):
Es wird bislang mit dem „Automaten“ nur ein Teil der möglichen Attribute unterstützt.
Es wird nur Version 2.1 gelesen. Version 3 und 4 unterscheiden sich erheblich.
Wichtiger jedoch ist die Tatsache, dass schon in der Spezifikation der vCard (siehe Referenzen) eine „Grammatik“ (ansatzweise) definiert wird.
Texte auszuwerten (zu parsen) auf Basis einer Grammatik ist Aufgabe eines Compilers und nicht eines Automaten.
3.2.1. Objekt-Spezifikation 2.1#
Es soll hier der Darstellung in Wikipedia gefolgt werden:
Attribut |
Muss |
Beschreibung |
Beispiel |
|---|---|---|---|
ADR |
n |
Strukturierte Darstellung der physischen Anschrift des vCard-Objekts. |
ADR;TYPE=home:;;Heidestrasse 17;Koeln;;51147;Germany |
AGENT |
n |
Informationen über eine andere Person, die im Namen des vCard-Objekts handeln soll. |
AGENT:http://de.wikipedia.org/wiki/007 |
BDAY |
n |
Geburtsdatum |
BDAY:19640812 |
BEGIN |
y |
Jede vCard muss mit dieser Eigenschaft beginnen. |
BEGIN:VCARD |
CATEGORIES |
n |
Liste von Eigenschaften |
CATEGORIES:swimmer,biker |
n |
E-Mail-Adresse |
EMAIL:erika@mustermann.de |
|
END |
y |
Jede vCard muss mit dieser Eigenschaft enden. |
END:VCARD |
FN |
n |
Formatierte Zeichenfolge mit dem vollständigen Namen |
FN:Dr. Erika Mustermann |
GEO |
n |
Längen- und Breitengrad. |
GEO:50.858,7.0885 |
KEY |
n |
Öffentlicher Schlüssel |
KEY;PGP:http://example.org/key.pgp ODER KEY;PGP;ENCODING=BASE64:[base64-data] |
LABEL |
n |
Stellt den eigentlichen Adress-Text dar |
LABEL;TYPE=HOME:Heidestrasse 17n51147 KoelnnDeutschland |
LOGO |
n |
Logo der Organisation, mit der die Person in Beziehung steht |
LOGO;PNG:http://example.org/logo.png ODER LOGO;PNG;ENCODING=BASE64:[base64-data] |
MAILER |
n |
Genutztes E-Mail-Programm (Client) |
MAILER:Thunderbird |
N |
y |
Strukturierte Darstellung vom Namen der Person |
N:Mustermann;Erika;;Dr.; |
NOTE |
n |
Zusätzliche Informationen oder Kommentar |
NOTE:Eine fiktive Person |
ORG |
n |
Name und gegebenenfalls Abteilung der Organisation |
ORG:Google;GMail Team;Spam Detection Squad |
PHOTO |
n |
Bild |
PHOTO;JPEG:http://example.org/photo.jpg ODER PHOTO;JPEG;ENCODING=BASE64:[base64-data] |
PROFILE |
n |
Legt fest, dass die vCard eine vCard ist. |
PROFILE:VCARD |
REV |
n |
Zeitstempel der letzten Aktualisierung der vCard. |
REV:20140301T221110Z |
ROLE |
n |
Rolle oder Beruf |
ROLE:Executive |
SORT-STRING |
n |
Zeichenkette, die die Sortierreihenfolge beschreibt |
SORT-STRING:Mustermann |
SOUND |
n |
Gibt standardmäßig die Aussprache der FN-Eigenschaft an |
SOUND;OGG:http://example.org/sound.ogg ODER SOUND;OGG;ENCODING=BASE64:[base64-data] |
SOURCE |
n |
URL, die verwendet werden kann, um die neueste Version dieser vCard zu erhalten. |
SOURCE:http://mustermann.de/vCard.vcf |
TEL |
n |
Normalform einer numerischen Zeichenkette für eine Telefonnummer |
TEL;TYPE=CELL,HOME:(0170) 1234567 |
TITLE |
n |
Angabe der Stellenbezeichnung, funktionellen Stellung |
TITLE:V.P. Research and Development |
TZ |
n |
Zeitzone |
TZ:+0100 |
UID |
n |
UUID, die eine persistente, global eindeutige Kennung darstellt. |
UID:urn:uuid:550e8400-e29b-11d4-a716-44665544ffff |
URL |
n |
URL zu einer Website. |
URL:http://www.mustermann.de |
VERSION |
y |
Version der vCard-Spezifikation. |
VERSION:2.1 |
{kind=link}
{kind=link}
Offensichtlich sind nur sehr wenige Eigenschaften / Attribute wirklich notwendig:
Attribut |
Muss |
Beschreibung |
Beispiel |
|---|---|---|---|
BEGIN |
y |
Jede vCard muss mit dieser Eigenschaft beginnen. |
BEGIN:VCARD |
END |
y |
Jede vCard muss mit dieser Eigenschaft enden. |
END:VCARD |
N |
y |
Strukturierte Darstellung vom Namen der Person |
N:Mustermann;Erika;;Dr.; |
VERSION |
y |
Version der vCard-Spezifikation. |
VERSION:2.1 |
3.2.2. Was fehlt#
Des weiteren wird mit der Auflistung aller Attribute deutlich, welche Attribute in der ersten Version es Konverters erkannt werden und welche fehlen (in der folgenden Tabelle mit „n“ gekennzeichnet):
Attribut |
DEA |
|---|---|
ADR |
y |
AGENT |
n |
BDAY |
n |
BEGIN |
y |
CATEGORIES |
y |
y |
|
END |
y |
FN |
y |
GEO |
n |
KEY |
n |
LABEL |
n |
LOGO |
n |
MAILER |
n |
N |
y |
NOTE |
n |
ORG |
y |
PHOTO |
n |
PROFILE |
n |
REV |
n |
ROLE |
n |
SORT-STRING |
n |
SOUND |
n |
SOURCE |
n |
TEL |
y |
TITLE |
y |
TZ |
n |
UID |
n |
URL |
n |
VERSION |
y |
3.3. Grammatik – Spezifikation#
3.3.1. versit Consortium#
In erster Näherung wird als Grundlage die Grammatik in „vCard – The Electronic Business vCard, Version 2.1; September 18, 1996“ gewählt (siehe Referenzen).
In Kapitel 2.9 wird eine formale Definition in Backus-Naur Notation (BNF) vorgestellt:
This syntax is written according to the form described in RFC 822, but it references just this small subset of RFC 822 literals:
CR = <ASCII CR, carriage return> ; ( 15, 13.)
LF = <ASCII LF, linefeed> ; ( 12, 10.)
CRLF = CR LF
SPACE = <ASCII SP, space> ; ( 40, 32.)
HTAB = <ASCII HT, horizontal-tab> ; ( 11, 9.)
All literal property names are valid as upper, lower, or mixed case.
ws = 1*(SPACE / HTAB)
; “whitespace,” one or more spaces or tabs
wsls = 1*(SPACE / HTAB / CRLF)
; whitespace with line separators
word = <any printable 7bit us-ascii except []=:., >
groups = groups “.” word
/ word
vcard_file = [wsls] vcard [wsls]
vcard = “BEGIN” [ws] “:” [ws] “VCARD” [ws] 1*CRLF
items *CRLF “END” [ws] “:” [ws] “VCARD”
items = items *CRLF item
/ item
; these may be “folded”
item = [groups “.”] name
[params] “:” value CRLF
/ [groups “.”] “ADR”
[params] “:” addressparts CRLF
/ [groups “.”] “ORG”
[params] “:” orgparts CRLF
/ [groups “.”] “N”
[params] “:” nameparts CRLF
/ [groups “.”] “AGENT”
[params] “:” vcard CRLF
; these may be “folded”
name = “LOGO” / “PHOTO” / “LABEL” / “FN” / “TITLE”
/ “SOUND” / “VERSION” / “TEL” / “EMAIL” / “TZ” / “GEO” / “NOTE”
/ “URL” / “BDAY” / “ROLE” / “REV” / “UID” / “KEY”
/ “MAILER” / “X-” word
; these may be “folded”
value = 7bit / quoted-printable / base64
7bit = <7bit us-ascii printable chars, excluding CR LF>
8bit = <MIME RFC 1521 8-bit text>
quoted-printable = <MIME RFC 1521 quoted-printable text>
base64 = <MIME RFC 1521 base64 text>
; the end of the text is marked with two CRLF sequences
; this results in one blank line before the start of the next property
params = “;” [ws] paramlist
paramlist = paramlist [ws] “;” [ws] param
/ param
param = “TYPE” [ws] “=“ [ws] ptypeval
/ “VALUE” [ws] “=“ [ws] pvalueval
/ “ENCODING” [ws] “=“ [ws] pencodingval
/ “CHARSET” [ws] “=“ [ws] charsetval
/ “LANGUAGE” [ws] “=“ [ws] langval
/ “X-” word [ws] “=“ [ws] word
/ knowntype
ptypeval = knowntype / “X-” word
pvalueval = “INLINE” / “URL” / “CONTENT-ID” / “CID” / “X-” word
pencodingval = “7BIT” / “8BIT” / “QUOTED-PRINTABLE” / “BASE64” / “X-” word
charsetval = <a character set string as defined in Section 7.1 of
RFC 1521>
langval = <a language string as defined in RFC 1766>
addressparts = 0*6(strnosemi “;”) strnosemi
; PO Box, Extended Addr, Street, Locality, Region, Postal Code,
Country Name
orgparts = *(strnosemi “;”) strnosemi
; First is Organization Name, remainder are Organization Units.
nameparts = 0*4(strnosemi “;”) strnosemi
; Family, Given, Middle, Prefix, Suffix.
; Example:Public;John;Q.;Reverend Dr.;III, Esq.
strnosemi = *(*nonsemi (“\;” / “\” CRLF)) *nonsemi
; To include a semicolon in this string, it must be escaped
; with a “\” character.
nonsemi = <any non-control ASCII except “;”>
knowntype = “DOM” / “INTL” / “POSTAL” / “PARCEL” / “HOME” / “WORK”
/ “PREF” / “VOICE” / “FAX” / “MSG” / “CELL” / “PAGER”
/ “BBS” / “MODEM” / “CAR” / “ISDN” / “VIDEO”
/ “AOL” / “APPLELINK” / “ATTMAIL” / “CIS” / “EWORLD”
/ “INTERNET” / “IBMMAIL” / “MCIMAIL”
/ “POWERSHARE” / “PRODIGY” / “TLX” / “X400”
/ “GIF” / “CGM” / “WMF” / “BMP” / “MET” / “PMB” / “DIB”
/ “PICT” / “TIFF” / “PDF” / “PS” / “JPEG” / “QTIME”
/ “MPEG” / “MPEG2” / “AVI”
/ “WAVE” / “AIFF” / “PCM”
/ “X509” / “PGP”
3.3.2. ANTLR#
Die obige Grammatik hat zwei Arten von Regeln:
lexikalische Regeln
Das sind Regeln zur Definition einzelner „Worte“, Token die verwendet werden dürfen nach bestimmten Regeln.
Beispiel
CR = <ASCII CR, carriage return> ; ( 15, 13.) LF = <ASCII LF, linefeed> ; ( 12, 10.) CRLF = CR LF SPACE = <ASCII SP, space> ; ( 40, 32.) HTAB = <ASCII HT, horizontal-tab> ; ( 11, 9.) word = <any printable 7bit us-ascii except []=:., >syntaktische Regeln
Das sind Regeln mit denen Satzstrukturen beschrieben werden.
Beispiel
vcard = “BEGIN” [ws] “:” [ws] “VCARD” [ws] 1*CRLF items *CRLF “END” [ws] “:” [ws] “VCARD”
Es soll zunächst der selbe Umfang realisiert werden, wie im vorigen Kapitel mit Hilfe des „Endlichen Automaten“. Eine Realisierung mit Compiler-Tools ist langfristig flexibler zu warten, als die erste Lösung.
Beginnen wir mit einem ersten Entwurf der elementaren „Token“, die erkannt sein wollen:
1 lexer grammar QLexerRules; 2 3 BEGIN : 'BEGIN' ; 4 END : 'END' ; 5 VCARD : 'VCARD' ; 6 VERSION : 'VERSION' ; 7 8 PROP_N : 'N' ; 9 PROP_FN : 'FN' ; 10 PROP_TEL : 'TEL' ; 11 PROP_CAT : 'CATEGORIES' ; 12 PROP_MAIL: 'EMAIL' ; 13 PROP_ORG : 'ORG' ; 14 PROP_TIT : 'TITLE' ; 15 16 BBS : 'BBS' ; 17 CAR : 'CAR' ; 18 CELL : 'CELL'; 19 CHARSET : 'CHARSET' ; 20 ENCODING: 'ENCODING' ; 21 FAX : 'FAX' ; 22 HOME : 'HOME' ; 23 INTERNET : 'INTERNET' ; 24 ISDN : 'ISDN' ; 25 MODEM : 'MODEM' ; 26 MSG : 'MSG'; 27 PAGER : 'PAGER' ; 28 PREF : 'PREF' ; 29 VIDEO : 'VIDEO' ; 30 VOICE : 'VOICE' ; 31 WORK : 'WORK' ; 32 33 QUOTPRINT : ('=' [0-9ABCDEF]*)+ ; 34 W7BIT : ('-' | '+' | [a-zA-Z0-9_~., @#])+ ; // alles Zeichen erlaubt; außer Operatoren 35 36 CRLF : '\r'? '\n' ;
Auf der linken Seite (vor dem „:“) findet man einen Alias-Namen, des gleich bei der Definition der Grammatik verwendet wird.
Auf der rechten Seite ist die Zeichenkette definiert, die damit beim Lesen erfasst wird. Das sind einzelne Wörter wie „EMAIL“ oder Zeichenketten, die über reguläre Ausdrücke festgelegt werden.
Mit obiger Definition kann die vCard-Datei, die bislang als Aufgabe zu parsen war, gelesen werden.
Eine Grammatik, die diese Token verwendet kann wie folgt aussehen:
1grammar QLang; 2 3prog: CRLF* (vcard)* # vcf_prog 4 ; 5 6vcard : begin version items end # vcf_card 7 ; 8 9version : VERSION ':' '2.1' CRLF # vcf_version 10 ; 11 12begin : BEGIN ':' VCARD CRLF # vcf_begin 13 ; 14 15end : END ':' VCARD CRLF # vcf_end 16 ; 17 18items : (item)* 19 ; 20 21item : item_rec CRLF 22 | CRLF 23 ; 24 25item_rec : name 26 | form_name 27 | telefon 28 | mail 29 | categorie 30 | org 31 | title 32 ; 33 34name : PROP_N (';' prop_param)* ':' name_rhs # vcf_name 35 ; 36 37prop_param : ENCODING '=' pencodingval # val_enc 38 | CHARSET '=' charsetval # val_char 39 ; 40 41name_rhs : n_family? ';' n_given? ';' n_add? ';' n_prefix? ';' n_suffix? 42 ; 43 44n_family : value ; 45n_given : value ; 46n_add : value ; 47n_prefix : value ; 48n_suffix : value ; 49 50value : text | quotprint | ('-')+ ; 51text : W7BIT ; 52quotprint : QUOTPRINT ; 53 54form_name : PROP_FN (';' prop_param)* ':' value ; 55 56telefon : PROP_TEL (';' tel_param)* ':' value ; 57 58tel_param : prop_param 59 | PREF 60 | WORK 61 | HOME 62 | VOICE 63 | FAX 64 | MSG 65 | CELL 66 | PAGER 67 | BBS 68 | MODEM 69 | CAR 70 | ISDN 71 | VIDEO 72 ; 73 74pencodingval : '7BIT' | '8BIT' | 'QUOTED-PRINTABLE' | 'BASE64' ; 75charsetval : W7BIT ; 76 77mail : PROP_MAIL (';' mail_param)* ':' value # vcf_mail 78 ; 79 80mail_param : PREF 81 | WORK 82 | HOME 83 | INTERNET 84 ; 85 86categorie : PROP_CAT ':' value ; 87org : PROP_ORG ':' value ; 88title : PROP_TIT ':' value ;
Die Regeln haben wie bei der lexikalischen Analyse einen Alias (Name der Produktion) und eine oder mehrere Definitionen. Die Namen der Regeln sind klein geschrieben, die der Token sind in Großbuchstaben.
3.4. Test der Grammatik#
Ein wichtiges Merkmal von ANTLR4 ist die Abkehr vom Performance-Gedanken hin zu der Wartbarkeit des Codes. Schon die Grammatik unterscheidet sich erheblich von den klassischen Ansätzen [Dragon] und unterstützt den Entwickler.
Warnung
Im Umkehrschluss bedeutet die Priorisierung der Wartbarkeit, dass das Tool nicht optimal ist, wenn Performance im Vordergrund steht. Wenn Performance ein „Muss“ ist, sollte man sich doch mit lex/yacc, flex/bison beschäftigen.
Die Wartbarkeit des Codes wird unterstützt durch die Trennung von Grammatik und Source Code. Das Herzstück ist der AST (Abstract Syntax Tree), der zur Laufzeit erzeugt wird, und den man mit den generierten Methoden abarbeiten kann.
Dieser AST lässt sich bei Vorliegen der Grammatik visualisieren, ohne dass man eine Zeile Java/Python/… schreiben muss und zwar wie folgt:
Es werden die Java-Klassen aus der Grammatik generiert, im Beispiel
java -jar /opt/antlr/antlr4/antlr-4.9-complete.jar -visitor QLang.g4
Die Klassen werden übersetzt
javac QLang*.java
Das Testprogramm wird gestartet
java org.antlr.v4.gui.TestRig QLang prog -gui
Bemerkung
- Es empfiehlt sich einen Alias einzurichten, z.B.:
grun=“java org.antlr.v4.gui.TestRig“
Auf der Konsole werden die Testdaten eingegeben, z.B.
BEGIN:VCARD VERSION:2.1 N:Public;John;Quinlan;Mr.;Esq. END:VCARD
Der Syntax-Baum erscheint:
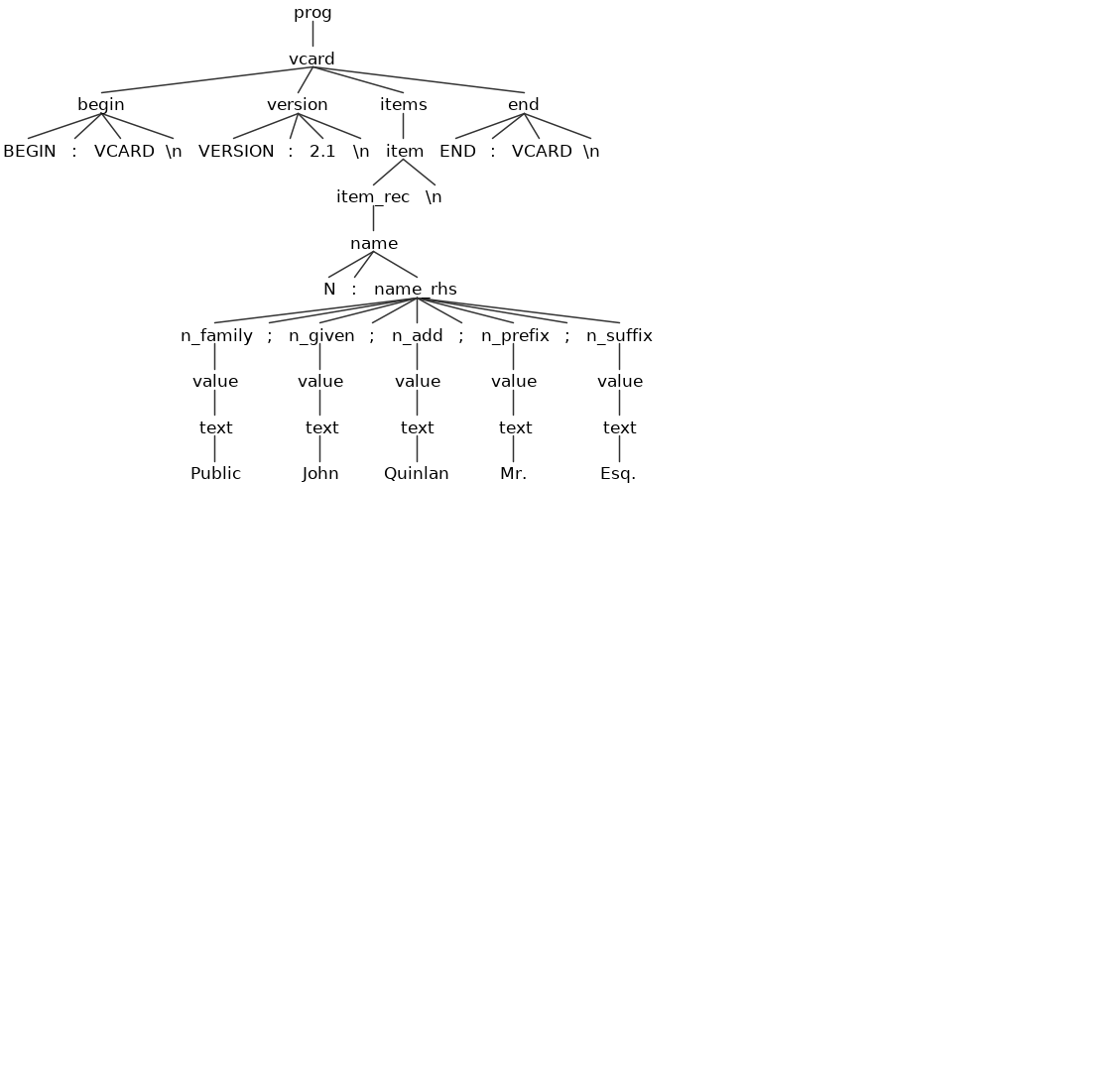
Man sieht auf den ersten Blick, dass man bei der Traversierung dieses Baumes die Information der vCard im Detail erhält.
Z.B. finden wir unter dem „name-Knoten“ alle Elemente des vCard „N-Items“ von „family“ bis „suffix“.
3.5. ANTLR Generatoren#
Auf Basis dieser Grammatik kann ANTLR (siehe Referenzen) Basis-Klassen für verschiedene Programmiersprachen generieren. Diese Basisklassen müssen nur angepasst werden, um den kompletten Parser zu erhalten.
Bemerkung
Es wird hier vorausgesetzt, dass antlr-4.9-complete.jar lokal installiert ist unter /opt/antlr/antlr4.
Um die Basisklassen für python3 zu erhalten, wird wie folgt vorgegangen:
Die Grammatik wird in einer Datei mit Namen Qlang.g4 gespeichert.
Es wird folgender Aufruf genutzt:
java -jar /opt/antlr/antlr4/antlr-4.9-complete.jar -visitor -Dlanguage=Python3 QLang.g4
Anschliessend findet man die folgenden generierten python-Dateien vor
QLangLexer.py
QLangListener.py
QLangParser.py
QLangVisitor.py
Im Folgenden werden wir mit dem Listener-Konzept arbeiten, so dass ein genauerer Blick auf QLangListener.py geworfen werden muss.
Man findet eine Klasse vor, die für jede Produktion der Grammatik eine „enter“- und eine „exit“-Methode definiert:
# This class defines a complete listener for a parse tree produced by QLangParser. class QLangListener(ParseTreeListener): # Enter a parse tree produced by QLangParser#vcf_prog. def enterVcf_prog(self, ctx:QLangParser.Vcf_progContext): pass # Exit a parse tree produced by QLangParser#vcf_prog. def exitVcf_prog(self, ctx:QLangParser.Vcf_progContext): pass # ...
Die Namen der Methoden enden entweder mit dem Namen der Regel oder mit einem selbst gewähten Namen am Ende der Regel (hier: „# vcf_prog“), der in der Grammatik angegeben ist – Beispiel:
prog: CRLF* (vcard)* # vcf_prog
erzeugt genau die obigen Methodennamen.
3.6. Fleisch ans Skelett#
Der wesentliche Teil der Implementierung des Parsers besteht nun darin, eine abgeleitete Klasse von QLangListener zu erstellen, die die Daten bei dem Durchlaufen des AST „einsammelt“.
In unserem Beispiel kann die wie folgt aussehen:
1class CVcardListener(QLangListener):
2 def __init__(self):
3 super(CVcardListener, self).__init__()
4 self.log = get_logger()
5 self._result = None
6 self._adr_lst = [] # [CDcVcard]
7 self.adr_hash = {} # key == CDcVcard.n.__repr__; value == CDcVcard
8
9 self._encoding = None
10 self._is_quotprint = False
11 self._is_base64 = False
12 self._text = None
13 self._name_obj = empty_n()
14 self._vcard_obj = empty_vcard()
15
16 @property
17 def result(self):
18 return self._result
19
20 def gen_adresses(self) -> CDcVcard:
21 for k, ao in self.adr_hash.items():
22 yield ao
23
24 # Exit a parse tree produced by QLangParser#prog.
25 def exitVcf_prog(self, ctx: QLangParser.ProgContext):
26 self._result = 'IO'
27 self.log.debug('prog')
28 pass
29
30 # Exit a parse tree produced by QLangParser#vcf_card.
31 def exitVcf_card(self, ctx: QLangParser.Vcf_cardContext):
32 pass
33
34 # Exit a parse tree produced by QLangParser#vcf_begin.
35 def exitVcf_begin(self, ctx: QLangParser.Vcf_beginContext):
36 self.log.debug('begin')
37
38 # Exit a parse tree produced by QLangParser#vcf_end.
39 def exitVcf_end(self, ctx: QLangParser.Vcf_endContext):
40 self._vcard_obj.n = self._name_obj
41 k = self._name_obj.__repr__()
42 if k not in self.adr_hash:
43 self.adr_hash[k] = self._vcard_obj
44 self.log.info(f' {self._vcard_obj}')
45 self._vcard_obj = empty_vcard()
46 self._name_obj = empty_n()
47 self.log.debug('end')
48
49 def enterItem(self, ctx: QLangParser.ItemContext):
50 self._encoding = None
51 self._is_quotprint = False
52 self._is_base64 = False
53
54 def enterQuotprint(self, ctx: QLangParser.QuotprintContext):
55 self._is_quotprint = True
56
57 def exitValue(self, ctx: QLangParser.ValueContext):
58 self._text = ctx.getText() if ctx.getText() else ''
59 if self._is_quotprint:
60 self._text = to_str(decodestring(self._text))
61 pass
62
63 def exitN_add(self, ctx: QLangParser.N_addContext):
64 self._name_obj.middle = self._text
65
66 def exitN_family(self, ctx: QLangParser.N_familyContext):
67 self._name_obj.family = self._text
68
69 def exitN_given(self, ctx: QLangParser.N_givenContext):
70 self._name_obj.given = self._text
71
72 def exitN_prefix(self, ctx: QLangParser.N_prefixContext):
73 self._name_obj.prefix = self._text
74
75 def exitN_suffix(self, ctx: QLangParser.N_suffixContext):
76 self._name_obj.suffix = self._text
77
78 # Exit a parse tree produced by QLangParser#vcf_name.
79 def exitName_rhs(self, ctx: QLangParser.Name_rhsContext):
80 self.log.debug(f'N: {self._name_obj}')
81
82 def exitForm_name(self, ctx: QLangParser.Form_nameContext):
83 prop = self._text
84 self.log.debug(f'FN: {prop}')
85 self._vcard_obj.fn = prop
86
87 def exitTelefon(self, ctx: QLangParser.TelefonContext):
88 prop = self._text
89 self.log.debug(f'TEL: {prop}')
90 self._vcard_obj.tel.append(prop)
91
92 def exitVcf_mail(self, ctx: QLangParser.Vcf_mailContext):
93 prop = self._text
94 self.log.debug(f'MAIL: {prop}')
95 self._vcard_obj.mail = prop
96
97 def exitCategorie(self, ctx: QLangParser.CategorieContext):
98 prop = self._text
99 self.log.debug(f'CATEGORIES: {prop}')
100 self._vcard_obj.categorie = prop
101
102 def exitTitle(self, ctx: QLangParser.TitleContext):
103 prop = self._text
104 self.log.debug(f'TITLE: {prop}')
105 self._vcard_obj.title = prop
106
107 def exitOrg(self, ctx: QLangParser.OrgContext):
108 prop = self._text
109 self.log.debug(f'ORG: {prop}')
110 self._vcard_obj.org = prop
Zum Verständnis, wie in dem Hash in Zeile 8 die Daten gesammelt werden, müssen noch zwei „Daten-Container-Klassen“ vorgestellt werden:
1# Property: N
2# Family, Given, Middle, Prefix, Suffix.
3# Example:Public;John;Q.;Reverend Dr.;III, Esq.
4@dataclass
5class CDcN:
6 family: str
7 given: str
8 middle: str
9 prefix: str
10 suffix: str
11
12 @property
13 def n_name(self):
14 rv = f'{self.family} {self.given} {self.middle} {self.prefix} {self.suffix}'
15 return rv
16
17
18@dataclass
19class CDcVcard:
20 n: CDcN
21 fn: str
22 tel: []
23 mail: str
24 categorie: str
25 org: str
26 title: str
27
28 def __lt__(self, other):
29 return self.n.n_name < other.n.n_name
30
31
32def empty_n():
33 rv = CDcN(
34 '',
35 '',
36 '',
37 '',
38 '',
39 )
40 return rv
41
42
43def empty_vcard():
44 rv = CDcVcard(empty_n(), '', [], '', '', '', '')
45 return rv
Man sieht, es wird für die gesamte vCard ein Container (CDcVcard) definiert und ein separater Container für den Namen (N-Tag) CDcN.
Beim Durchlaufen des AST werden die einzelnen Datenfelder gefüllt und in am Ende einer vCard (exitVcf_end, ab Zeile 40) in den Sammel-Hash eingetragen.
Duplikate werden ignoriert, wobei die „Gleichheit“ über den Namen verglichen wird.
3.7. Das Hauptprogramm#
Jetzt fehlt nur noch das Rahmenprogramm, um unsere Parser-Ableitung mit Daten zu füttern.
1class CqLangParser:
2 def __init__(self):
3 self.log = get_logger()
4 msg = 'QLang-Parser is starting.'
5 self.log.info(msg)
6 self.vcf_listener = CVcardListener()
7
8 def parse_vcf(self, src_txt):
9 _input = InputStream(src_txt)
10 lexer = QLangLexer(_input)
11 stream = CommonTokenStream(lexer)
12 parser = QLangParser(stream)
13
14 tree = parser.prog()
15 walker = ParseTreeWalker()
16 walker.walk(self.vcf_listener, tree)
17 return self.vcf_listener.result
Das Vorgehen ist mit ANTLR dabei immer dasselbe:
Der Source-Text wird in einen InputStream gewandelt (Zeile 10).
Der InputStream wird anschliessend in ein Lexer-Objekt überführt (Zeile 11).
Aus dem Lexer-Objekt wird eine Tokenstream generiert (Zeile 12).
Dieser Tokenstream dient dem Parser als Input (Zeile 13).
In Zeile 14 wird eine AST-Instanz erzeugt.
Ein AST-Durchlaufobjekt in Zeile 15 inspiziert mit seiner walk-Methode in Zeile 16 schließlich alle Knoten und ruft die entsprechenden Methoden unseres Listener-Objektes (Zeile 7) auf.
Am Ende enthält die Listener-Instanz den Hash mit allen vCard-Objekte.
3.8. Test Code#
Natürlich schreibt sich auch die einfache Ableitung der Parser-Klasse in der Regel nicht ohne anfängliche Fehler.
Es empfiehlt sich deshalb, parallel zur Klassen-Implementfierung Unit-Tests zu schreiben, z.B. mit einer Datei ./tests/test_vcf_simple.py:
1import unittest
2
3from qlib.qparser_vcf import CqLangParser
4
5CT001 = """BEGIN:VCARD
6VERSION:2.1
7END:VCARD
8"""
9
10CT002 = """BEGIN:VCARD
11VERSION:2.1
12N:Public;John;Quinlan;Mr.;Esq.
13END:VCARD
14"""
15
16
17class TestVcfParserMethods(unittest.TestCase):
18 def setUp(self):
19 pass
20
21 def test_vcf01(self):
22 p = CqLangParser()
23 self.assertEqual(p.parse_vcf(src_txt=CT001), 'IO')
24
25 def test_vcf02(self):
26 p = CqLangParser()
27 self.assertEqual(p.parse_vcf(src_txt=CT002), 'IO')
28
29 def tearDown(self):
30 pass
31
32
33if __name__ == '__main__':
34 unittest.main()
Ein Testlauf liefert folgendes Ergebnis
$ python -m tests.test_vcf_simple -v
test_vcf01 (__main__.TestVcfParserMethods) ... ok
test_vcf02 (__main__.TestVcfParserMethods) ... ok
----------------------------------------------------------------------
Ran 2 tests in 0.006s
3.9. DB-Import#
Wenn man sich die Grammatik der vCard ansieht (siehe die Spezifikation des versit Consortium), wird klar, dass es sich bei einer solchen Visitenkarte eigentlich um ein „Objekt“ handelt, dass mehr als 20 Entitäten haben kann und davon jeweils gleich mehrere, z.B. gibt es oft mehrere Telefonnummern oder Email-Adressen zu einer vCard.
Diese Tatsache führte zu dem „Workaround“ bei den Telefonnummern in den einzeiligen CSV-Einträgen.
Um ein Objekt mit beliebig vielen Eigenschaften zu speichern, bietet sich der Einsatz einer relationalen Datenbank an.
Glücklichwerweise braucht man weder ein „Oracle“ noch „Mircosoft“ oder AWS, um ein „state-of-the-art“ Datenbanksystem für diesen Zweck einzusetzen.
PostgreSQL ist ein Datenbanksystem, das nicht nur „mit allen Wassern gewaschen ist“ sondern auf Jahrzehnte „gereift“ ist und damit ideal für diesen Einsatz.
Bevor das Projekt „vCard-Import“ in ein ein RDBMS (PostgreSQL) gestartet wird, soll aber noch ein Kapitel über „Multi-Release“, „Multi-Cluster“ PostgreSQL geschrieben werden, welches dann die Basis für die Implementierung wird (voraussichtlich werden wir auch nicht um SQLAlchemy „herumkommen“).
3.10. Referenzen#
Referencen
[Dragon]Compilers: Principles, Techniques, and Tools; https://suif.stanford.edu/dragonbook/
URLs